 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Planning for Multi-Object Manipulation with Environment-Aware Relational Classifiers
May 18, 2023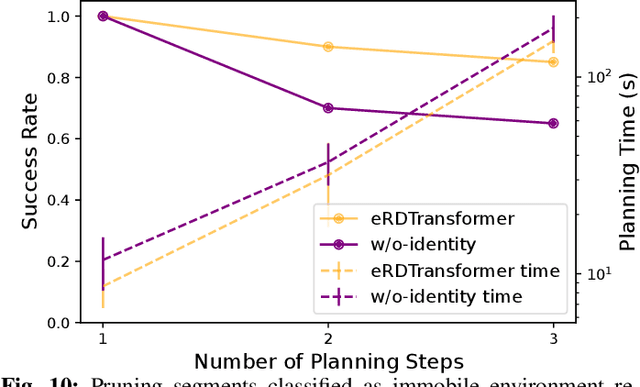
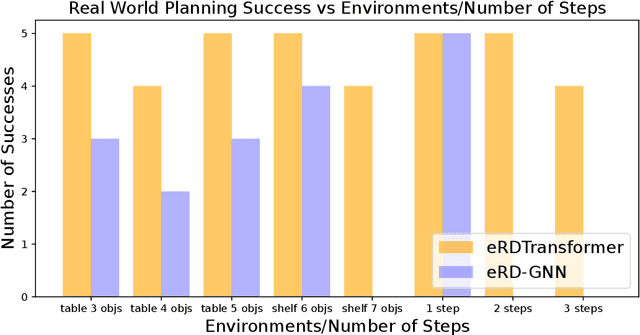


Objects rarely sit in isolation in everyday human environments. If we want robots to operate and perform tasks in our human environments, they must understand how the objects they manipulate will interact with structural elements of the environment for all but the simplest of tasks. As such, we'd like our robots to reason about how multiple objects and environmental elements relate to one another and how those relations may change as the robot interacts with the world. We examine the problem of predicting inter-object and object-environment relations between previously unseen objects and novel environments purely from partial-view point clouds. Our approach enables robots to plan and execute sequences to complete multi-object manipulation tasks defined from logical relations. This removes the burden of providing explicit, continuous object states as goals to the robot. We explore several different neural network architectures for this task. We find the best performing model to be a novel transformer-based neural network that both predicts object-environment relations and learns a latent-space dynamics function. We achieve reliable sim-to-real transfer without any fine-tuning. Our experiments show that our model understands how changes in observed environmental geometry relate to semantic relations between objects. We show more videos on our website: https://sites.google.com/view/erelationaldynamics.
Planning for Multi-Object Manipulation with Graph Neural Network Relational Classifiers
Sep 24, 2022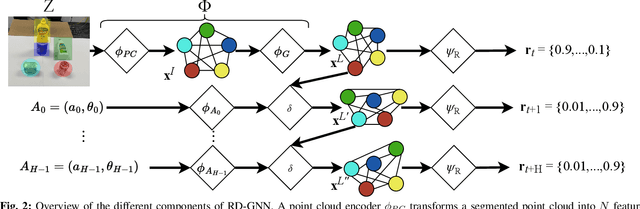

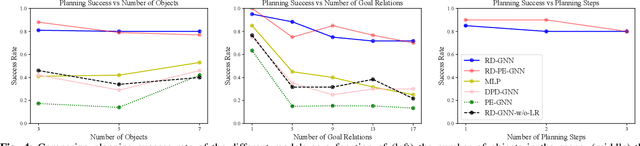
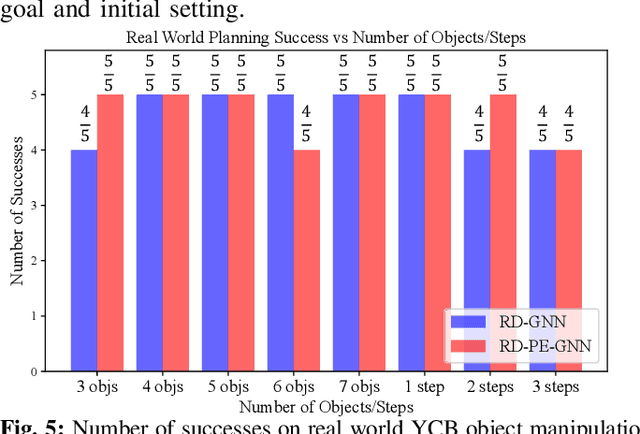
Objects rarely sit in isolation in human environments. As such, we'd like our robots to reason about how multiple objects relate to one another and how those relations may change as the robot interacts with the world. To this end, we propose a novel graph neural network framework for multi-object manipulation to predict how inter-object relations change given robot actions. Our model operates on partial-view point clouds and can reason about multiple objects dynamically interacting during the manipulation. By learning a dynamics model in a learned latent graph embedding space, our model enables multi-step planning to reach target goal relations. We show our model trained purely in simulation transfers well to the real world. Our planner enables the robot to rearrange a variable number of objects with a range of shapes and sizes using both push and pick and place skills.
Planning under Uncertainty to Goal Distributions
Nov 09, 2020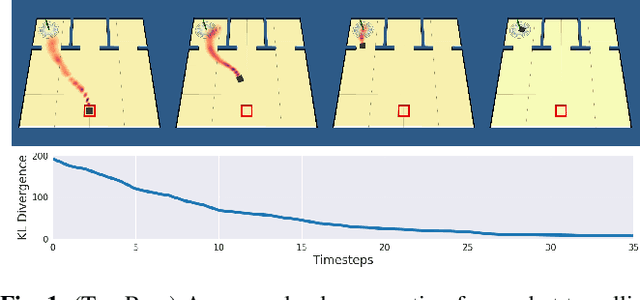
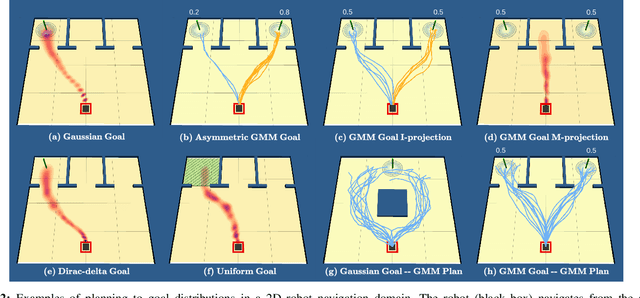

Goal spaces for planning problems are typically conceived of as subsets of the state space. It is common to select a particular goal state to plan to, and the agent monitors its progress to the goal with a distance function defined over the state space. Due to numerical imprecision, state uncertainty, and stochastic dynamics, the agent will be unable to arrive at a particular state in a verifiable manner. It is therefore common to consider a goal achieved if the agent reaches a state within a small distance threshold to the goal. This approximation fails to explicitly account for the agent's state uncertainty. Point-based goals further do not accommodate goal uncertainty that arises when goals are estimated in a data-driven way. We argue that goal distributions are a more appropriate goal representation and present a novel approach to planning under uncertainty to goal distributions. We use the unscented transform to propagate state uncertainty under stochastic dynamics and use cross-entropy method to minimize the Kullback-Leibler divergence between the current state distribution and the goal distribution. We derive reductions of our cost function to commonly used goal-reaching costs such as weighted Euclidean distance, goal set indicators, chance-constrained goal sets, and maximum expectation of reaching a goal point. We explore different combinations of goal distributions, planner distributions, and divergence to illustrate behaviors achievable in our framework.
Active Learning of Probabilistic Movement Primitives
Jun 29, 2019
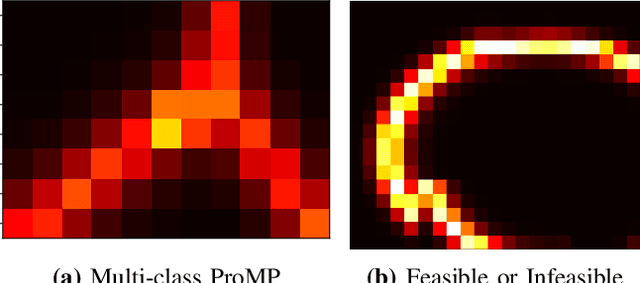
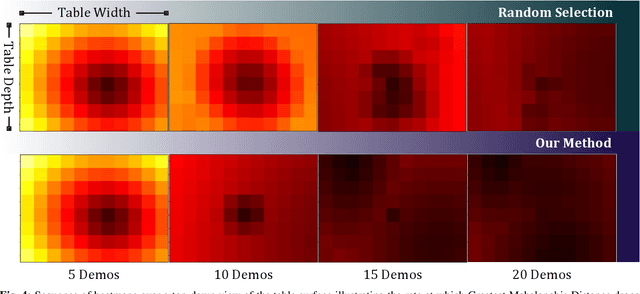
A Probabilistic Movement Primitive (ProMP) defines a distribution over trajectories with an associated feedback policy. ProMPs are typically initialized from human demonstrations and achieve task generalization through probabilistic operations. However, there is currently no principled guidance in the literature to determine how many demonstrations a teacher should provide and what constitutes a "good'" demonstration for promoting generalization. In this paper, we present an active learning approach to learning a library of ProMPs capable of task generalization over a given space. We utilize uncertainty sampling techniques to generate a task instance for which a teacher should provide a demonstration. The provided demonstration is incorporated into an existing ProMP if possible, or a new ProMP is created from the demonstration if it is determined that it is too dissimilar from existing demonstrations. We provide a qualitative comparison between common active learning metrics; motivated by this comparison we present a novel uncertainty sampling approach named "Greatest Mahalanobis Distance.'' We perform grasping experiments on a real KUKA robot and show our novel active learning measure achieves better task generalization with fewer demonstrations than a random sampling over the space.
Learning Task Constraints from Demonstration for Hybrid Force/Position Control
Nov 07, 2018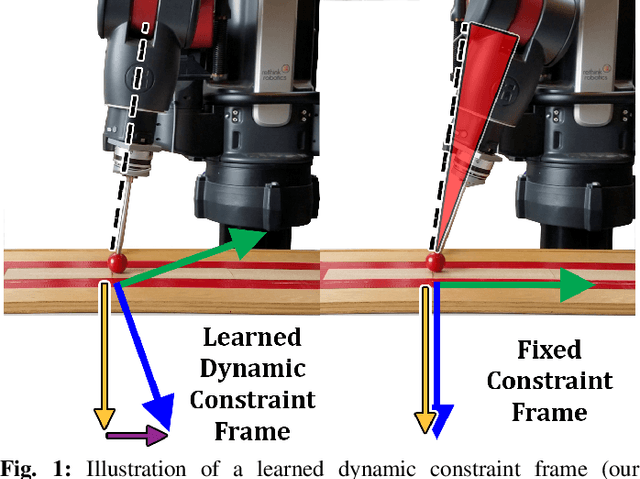

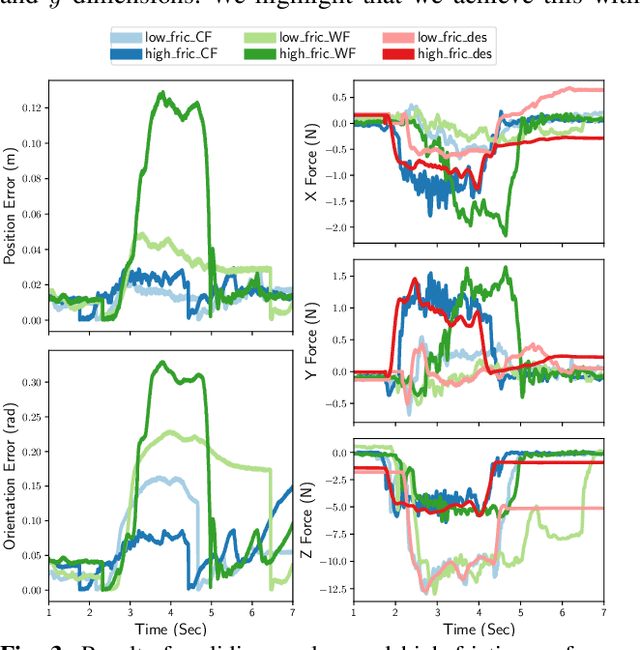
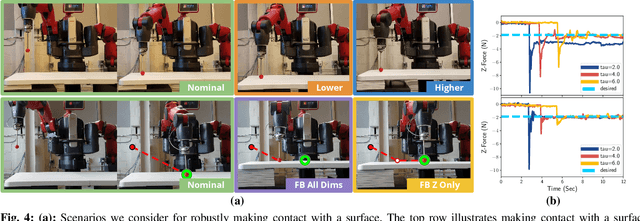
We present a novel method for learning hybrid force/position control from demonstration for multi-phase tasks. We learn a dynamic constraint frame aligned to the direction of desired force using Cartesian Dynamic Movement Primitives. Our approach allows tracking of desired forces while activating only one dimension of the constraint frame for force control. We find that controlling with respect to our learned constraint frame provides compensation for frictional forces while sliding without any explicit modeling of friction. We additionally propose extensions to the Dynamic Movement Primitive (DMP) formulation in order to robustly transition from free-space motion to in-contact motion in spite of environment uncertainty. We incorporate force feedback and a dynamically shifting goal into the DMP to reduce forces applied to the environment and retain stable contact when enabling force control. Our methods exhibit low impact forces on contact and low steady-state tracking error.