 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabSniper: Towards Accurate Table Detection & Structure Recognition for Bank Statements
Dec 17, 2024



Extraction of transaction information from bank statements is required to assess one's financial well-being for credit rating and underwriting decisions. Unlike other financial documents such as tax forms or financial statements, extracting the transaction descriptions from bank statements can provide a comprehensive and recent view into the cash flows and spending patterns. With multiple variations in layout and templates across several banks, extracting transactional level information from different table categories is an arduous task. Existing table structure recognition approaches produce sub optimal results for long, complex tables and are unable to capture all transactions accurately. This paper proposes TabSniper, a novel approach for efficient table detection, categorization and structure recognition from bank statements. The pipeline starts with detecting and categorizing tables of interest from the bank statements. The extracted table regions are then processed by the table structure recognition model followed by a post-processing module to transform the transactional data into a structured and standardised format. The detection and structure recognition architectures are based on DETR, fine-tuned with diverse bank statements along with additional feature enhancements. Results on challenging datasets demonstrate that TabSniper outperforms strong baselines and produces high-quality extraction of transaction information from bank and other financial documents across multiple layouts and templates.
MeronymNet: A Hierarchical Approach for Unified and Controllable Multi-Category Object Generation
Oct 17, 2021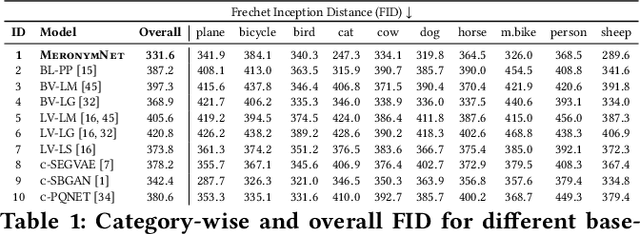
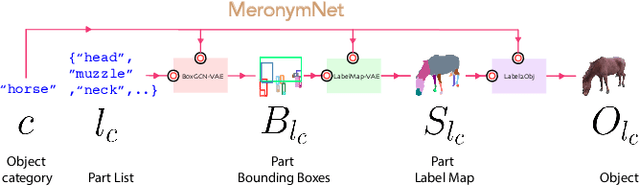
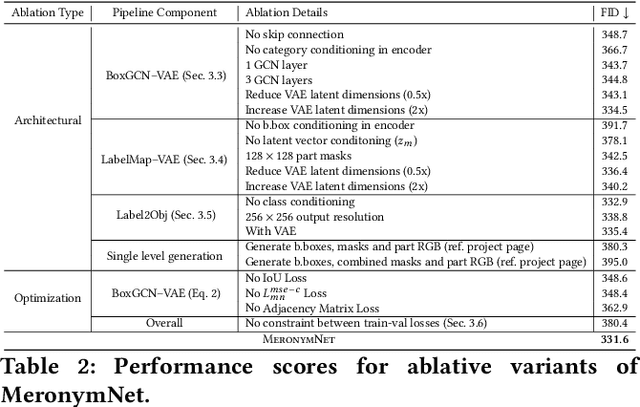
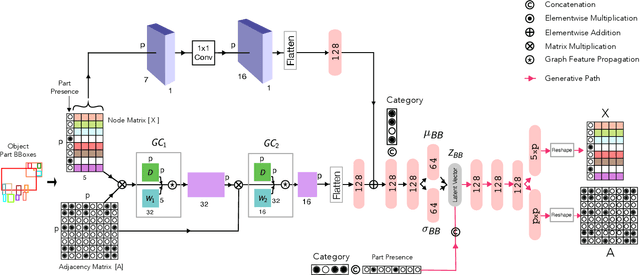
We introduce MeronymNet, a novel hierarchical approach for controllable, part-based generation of multi-category objects using a single unified model. We adopt a guided coarse-to-fine strategy involving semantically conditioned generation of bounding box layouts, pixel-level part layouts and ultimately, the object depictions themselves. We use Graph Convolutional Networks, Deep Recurrent Networks along with custom-designed Conditional Variational Autoencoders to enable flexible, diverse and category-aware generation of 2-D objects in a controlled manner. The performance scores for generated objects reflect MeronymNet's superior performance compared to multiple strong baselines and ablative variants. We also showcase MeronymNet's suitability for controllable object generation and interactive object editing at various levels of structural and semantic granularity.
Palmira: A Deep Deformable Network for Instance Segmentation of Dense and Uneven Layouts in Handwritten Manuscripts
Aug 21, 2021

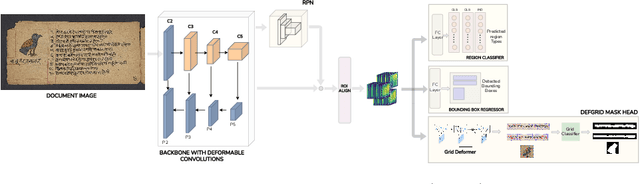
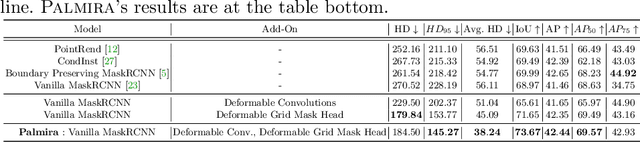
Handwritten documents are often characterized by dense and uneven layout. Despite advances, standard deep network based approaches for semantic layout segmentation are not robust to complex deformations seen across semantic regions. This phenomenon is especially pronounced for the low-resource Indic palm-leaf manuscript domain. To address the issue, we first introduce Indiscapes2, a new large-scale diverse dataset of Indic manuscripts with semantic layout annotations. Indiscapes2 contains documents from four different historical collections and is 150% larger than its predecessor, Indiscapes. We also propose a novel deep network Palmira for robust, deformation-aware instance segmentation of regions in handwritten manuscripts. We also report Hausdorff distance and its variants as a boundary-aware performance measure. Our experiments demonstrate that Palmira provides robust layouts, outperforms strong baseline approaches and ablative variants. We also include qualitative results on Arabic, South-East Asian and Hebrew historical manuscripts to showcase the generalization capability of Palmira.
BoundaryNet: An Attentive Deep Network with Fast Marching Distance Maps for Semi-automatic Layout Annotation
Aug 21, 2021

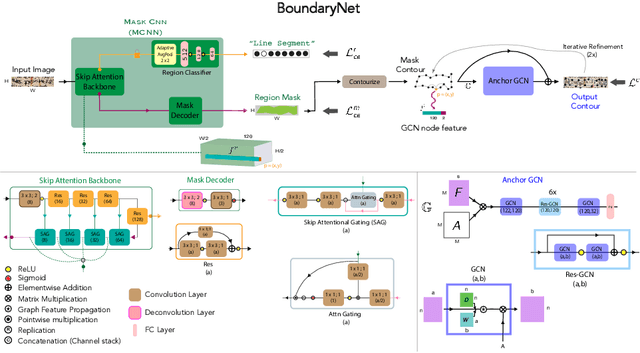

Precise boundary annotations of image regions can be crucial for downstream applications which rely on region-class semantics. Some document collections contain densely laid out, highly irregular and overlapping multi-class region instances with large range in aspect ratio. Fully automatic boundary estimation approaches tend to be data intensive, cannot handle variable-sized images and produce sub-optimal results for aforementioned images. To address these issues, we propose BoundaryNet, a novel resizing-free approach for high-precision semi-automatic layout annotation. The variable-sized user selected region of interest is first processed by an attention-guided skip network. The network optimization is guided via Fast Marching distance maps to obtain a good quality initial boundary estimate and an associated feature representation. These outputs are processed by a Residual Graph Convolution Network optimized using Hausdorff loss to obtain the final region boundary. Results on a challenging image manuscript dataset demonstrate that BoundaryNet outperforms strong baselines and produces high-quality semantic region boundaries. Qualitatively, our approach generalizes across multiple document image datasets containing different script systems and layouts, all without additional fine-tuning. We integrate BoundaryNet into a document annotation system and show that it provides high annotation throughput compared to manual and fully automatic alternatives.
Indiscapes: Instance Segmentation Networks for Layout Parsing of Historical Indic Manuscripts
Dec 15, 2019
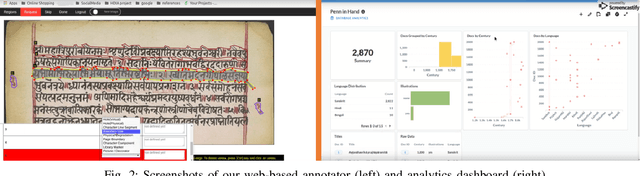
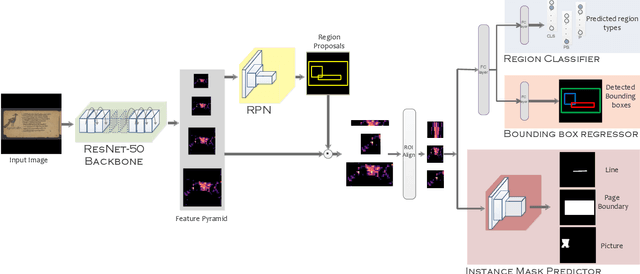

Historical palm-leaf manuscript and early paper documents from Indian subcontinent form an important part of the world's literary and cultural heritage. Despite their importance, large-scale annotated Indic manuscript image datasets do not exist. To address this deficiency, we introduce Indiscapes, the first ever dataset with multi-regional layout annotations for historical Indic manuscripts. To address the challenge of large diversity in scripts and presence of dense, irregular layout elements (e.g. text lines, pictures, multiple documents per image), we adapt a Fully Convolutional Deep Neural Network architecture for fully automatic, instance-level spatial layout parsing of manuscript images. We demonstrate the effectiveness of proposed architecture on images from the Indiscapes dataset. For annotation flexibility and keeping the non-technical nature of domain experts in mind, we also contribute a custom, web-based GUI annotation tool and a dashboard-style analytics portal. Overall, our contributions set the stage for enabling downstream applications such as OCR and word-spotting in historical Indic manuscripts at scale.