 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Decay Curves and Hyper-Parameter Grid Search Design for Recurrent Neural Architectures
Dec 08, 2020
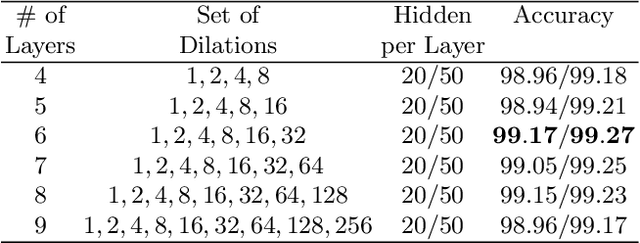
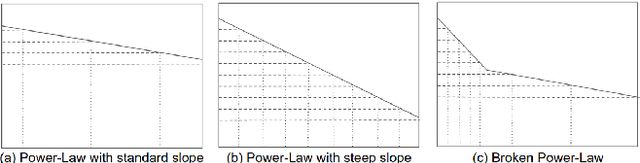
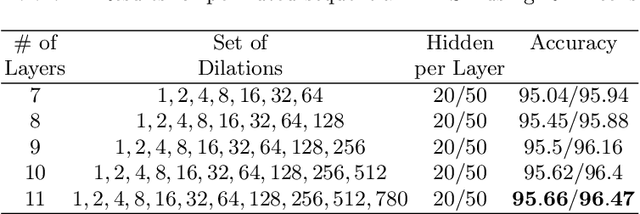
We present an approach to design the grid searches for hyper-parameter optimization for recurrent neural architectures. The basis for this approach is the use of mutual information to analyze long distance dependencies (LDDs) within a dataset. We also report a set of experiments that demonstrate how using this approach, we obtain state-of-the-art results for DilatedRNNs across a range of benchmark datasets.
Multi-Element Long Distance Dependencies: Using SPk Languages to Explore the Characteristics of Long-Distance Dependencies
Jul 13, 2019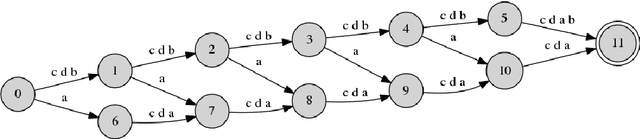
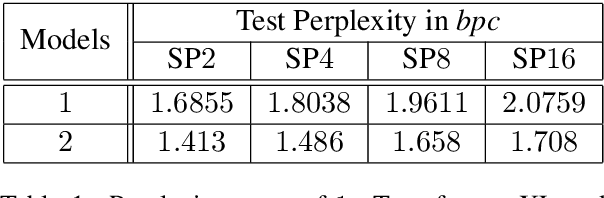
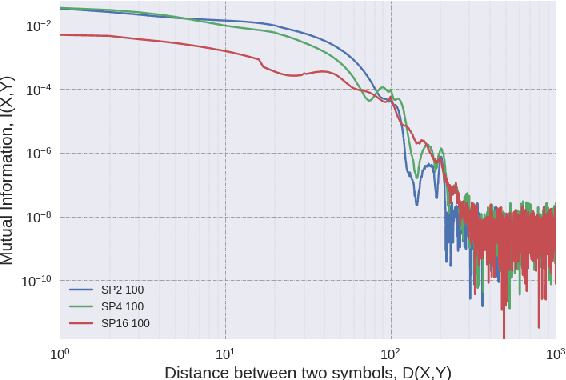
In order to successfully model Long Distance Dependencies (LDDs) it is necessary to understand the full-range of the characteristics of the LDDs exhibited in a target dataset. In this paper, we use Strictly k-Piecewise languages to generate datasets with various properties. We then compute the characteristics of the LDDs in these datasets using mutual information and analyze the impact of factors such as (i) k, (ii) length of LDDs, (iii) vocabulary size, (iv) forbidden subsequences, and (v) dataset size. This analysis reveal that the number of interacting elements in a dependency is an important characteristic of LDDs. This leads us to the challenge of modelling multi-element long-distance dependencies. Our results suggest that attention mechanisms in neural networks may aide in modeling datasets with multi-element long-distance dependencies. However, we conclude that there is a need to develop more efficient attention mechanisms to address this issue.
Generating Diverse and Meaningful Captions
Dec 19, 2018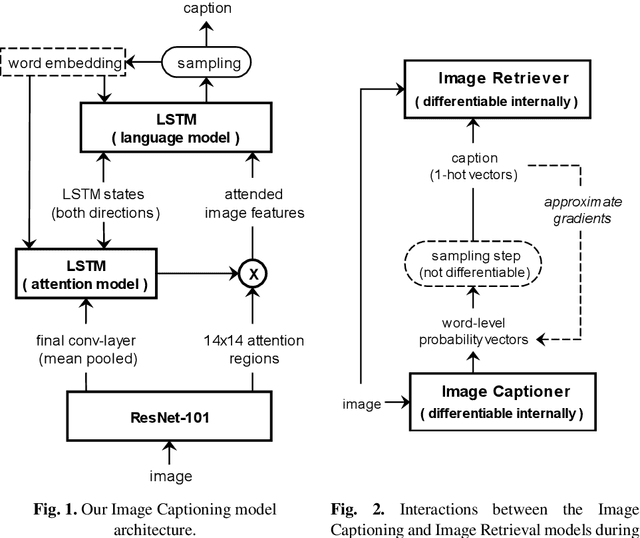
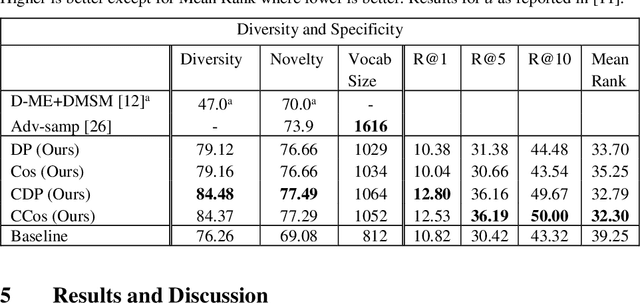
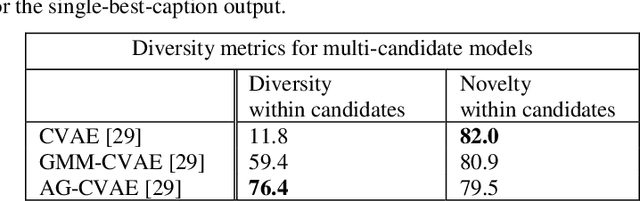
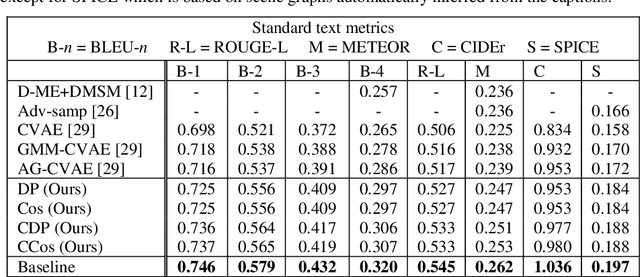
Image Captioning is a task that requires models to acquire a multi-modal understanding of the world and to express this understanding in natural language text. While the state-of-the-art for this task has rapidly improved in terms of n-gram metrics, these models tend to output the same generic captions for similar images. In this work, we address this limitation and train a model that generates more diverse and specific captions through an unsupervised training approach that incorporates a learning signal from an Image Retrieval model. We summarize previous results and improve the state-of-the-art on caption diversity and novelty. We make our source code publicly available online.
* Accepted for presentation at The 27th International Conference on Artificial Neural Networks (ICANN 2018)
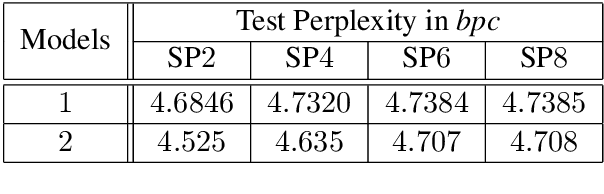
Using Regular Languages to Explore the Representational Capacity of Recurrent Neural Architectures
Aug 15, 2018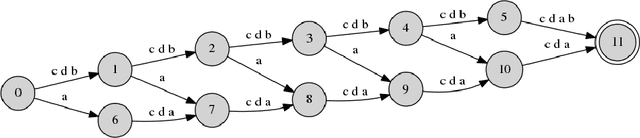
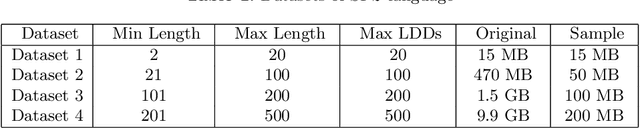

The presence of Long Distance Dependencies (LDDs) in sequential data poses significant challenges for computational models. Various recurrent neural architectures have been designed to mitigate this issue. In order to test these state-of-the-art architectures, there is growing need for rich benchmarking datasets. However, one of the drawbacks of existing datasets is the lack of experimental control with regards to the presence and/or degree of LDDs. This lack of control limits the analysis of model performance in relation to the specific challenge posed by LDDs. One way to address this is to use synthetic data having the properties of subregular languages. The degree of LDDs within the generated data can be controlled through the k parameter, length of the generated strings, and by choosing appropriate forbidden strings. In this paper, we explore the capacity of different RNN extensions to model LDDs, by evaluating these models on a sequence of SPk synthesized datasets, where each subsequent dataset exhibits a longer degree of LDD. Even though SPk are simple languages, the presence of LDDs does have significant impact on the performance of recurrent neural architectures, thus making them prime candidate in benchmarking tasks.