 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Driven Region Pointer Advancement for Controllable Image Captioning
Nov 30, 2020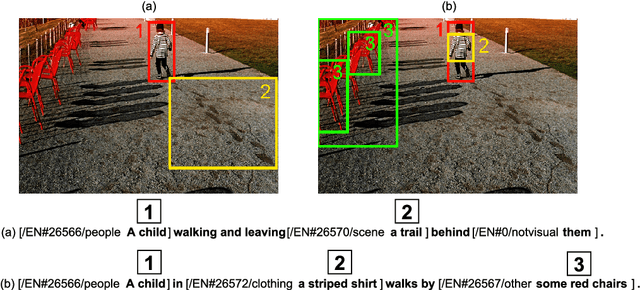



Controllable Image Captioning is a recent sub-field in the multi-modal task of Image Captioning wherein constraints are placed on which regions in an image should be described in the generated natural language caption. This puts a stronger focus on producing more detailed descriptions, and opens the door for more end-user control over results. A vital component of the Controllable Image Captioning architecture is the mechanism that decides the timing of attending to each region through the advancement of a region pointer. In this paper, we propose a novel method for predicting the timing of region pointer advancement by treating the advancement step as a natural part of the language structure via a NEXT-token, motivated by a strong correlation to the sentence structure in the training data. We find that our timing agrees with the ground-truth timing in the Flickr30k Entities test data with a precision of 86.55% and a recall of 97.92%. Our model implementing this technique improves the state-of-the-art on standard captioning metrics while additionally demonstrating a considerably larger effective vocabulary size.
Generating Diverse and Meaningful Captions
Dec 19, 2018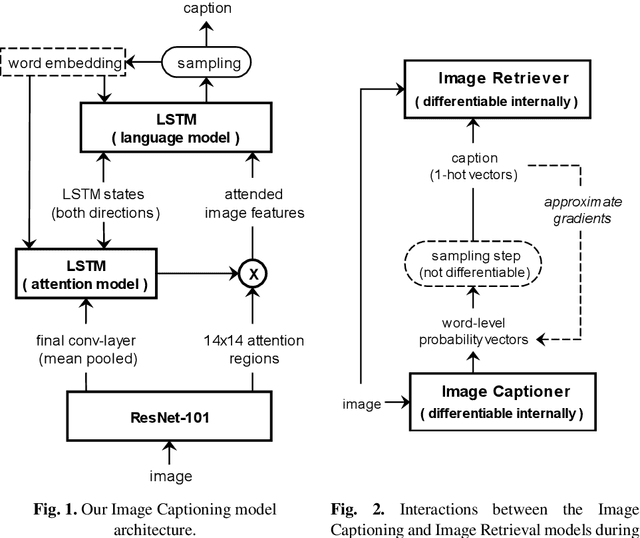
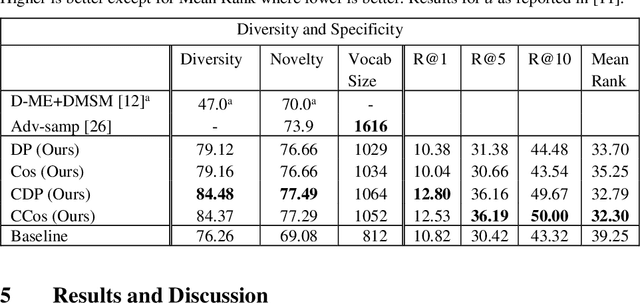
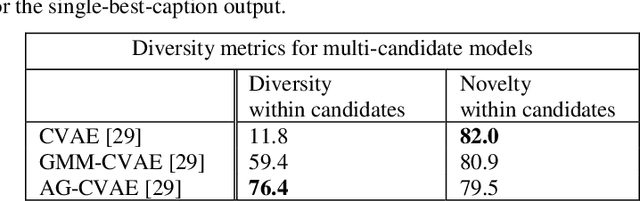
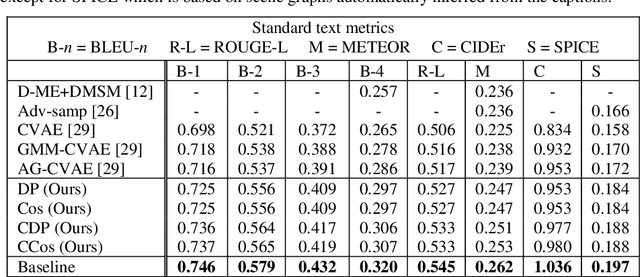
Image Captioning is a task that requires models to acquire a multi-modal understanding of the world and to express this understanding in natural language text. While the state-of-the-art for this task has rapidly improved in terms of n-gram metrics, these models tend to output the same generic captions for similar images. In this work, we address this limitation and train a model that generates more diverse and specific captions through an unsupervised training approach that incorporates a learning signal from an Image Retrieval model. We summarize previous results and improve the state-of-the-art on caption diversity and novelty. We make our source code publicly available online.
* Accepted for presentation at The 27th International Conference on Artificial Neural Networks (ICANN 2018)