Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Diverse and Meaningful Captions
Paper and Code
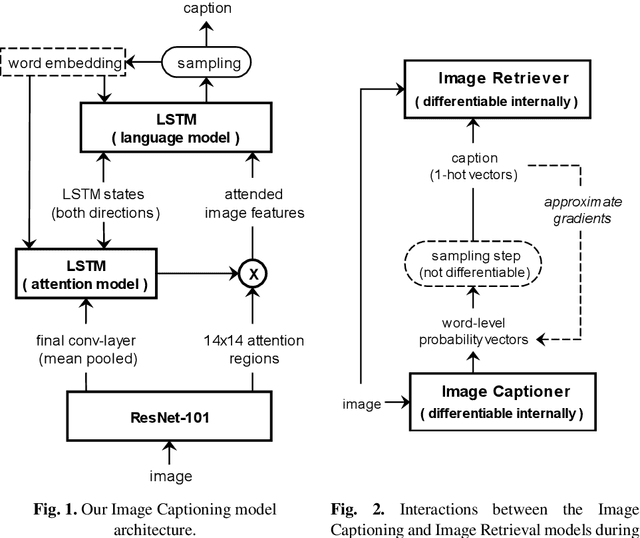
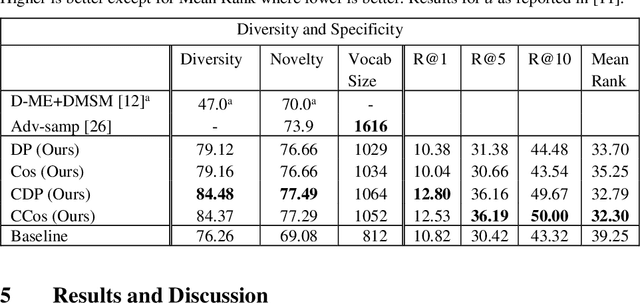
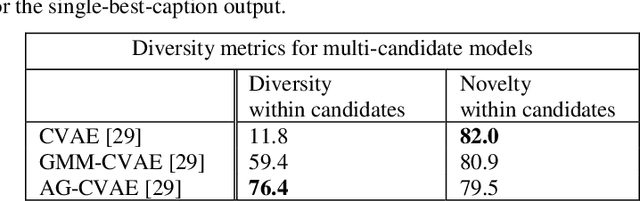
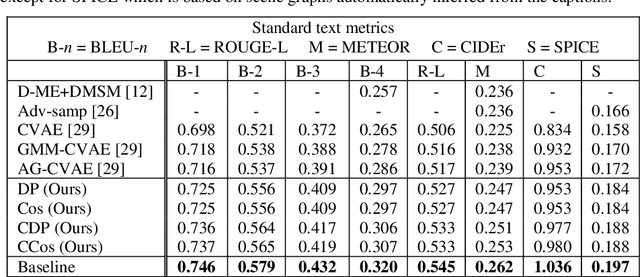
Image Captioning is a task that requires models to acquire a multi-modal understanding of the world and to express this understanding in natural language text. While the state-of-the-art for this task has rapidly improved in terms of n-gram metrics, these models tend to output the same generic captions for similar images. In this work, we address this limitation and train a model that generates more diverse and specific captions through an unsupervised training approach that incorporates a learning signal from an Image Retrieval model. We summarize previous results and improve the state-of-the-art on caption diversity and novelty. We make our source code publicly available online.
* Artificial Neural Networks and Machine Learning - ICANN 2018 (pp.
176-187). Springer International Publishing * Accepted for presentation at The 27th International Conference on
Artificial Neural Networks (ICANN 2018)
View paper on