 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-oriented Semantic Communications for Metaverse Construction via Generative AI and Optimal Transport
Nov 25, 2024



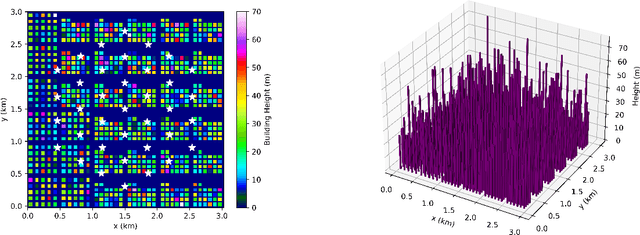
The emergence of the metaverse has boosted productivity and creativity, driving real-time updates and personalized content, which will substantially increase data traffic. However, current bit-oriented communication networks struggle to manage this high volume of dynamic information, restricting metaverse applications interactivity. To address this research gap, we propose a goal-oriented semantic communication (GSC) framework for metaverse. Building on an existing metaverse wireless construction task, our proposed GSC framework includes an hourglass network-based (HgNet) encoder to extract semantic information of objects in the metaverse; and a semantic decoder that uses this extracted information to reconstruct the metaverse content after wireless transmission, enabling efficient communication and real-time object behaviour updates to the scenery for metaverse construction task. To overcome the wireless channel noise at the receiver, we design an optimal transport (OT)-enabled semantic denoiser, which enhances the accuracy of metaverse scenery through wireless communication. Experimental results show that compared to the conventional metaverse construction, our proposed GSC framework significantly reduces wireless metaverse construction latency by 92.6\%, while improving metaverse object status accuracy and viewing experience by 45.6\% and 44.7\%, respectively.
Task-oriented Semantics-aware Communications for Robotic Waypoint Transmission: the Value and Age of Information Approach
Dec 20, 2023



The ultra-reliable and low-latency communication (URLLC) service of the fifth-generation (5G) mobile communication network struggles to support safe robot operation. Nowadays, the sixth-generation (6G) mobile communication network is proposed to provide hyper-reliable and low-latency communication to enable safer control for robots. However, current 5G/ 6G research mainly focused on improving communication performance, while the robotics community mostly assumed communication to be ideal. To jointly consider communication and robotic control with a focus on the specific robotic task, we propose task-oriented and semantics-aware communication in robotic control (TSRC) to exploit the context of data and its importance in achieving the task at both transmitter and receiver. At the transmitter, we propose a deep reinforcement learning algorithm to generate optimal control and command (C&C) data and a proactive repetition scheme (DeepPro) to increase the successful transmission probability. At the receiver, we design the value of information (VoI) and age of information (AoI) based queue ordering mechanism (VA-QOM) to reorganize the queue based on the semantic information extracted from the AoI and the VoI. The simulation results validate that our proposed TSRC framework achieves a 91.5% improvement in the mean square error compared to the traditional unmanned aerial vehicle control framework.
Path Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay
Aug 30, 2021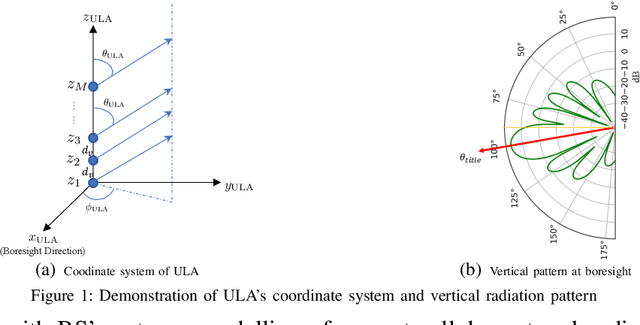
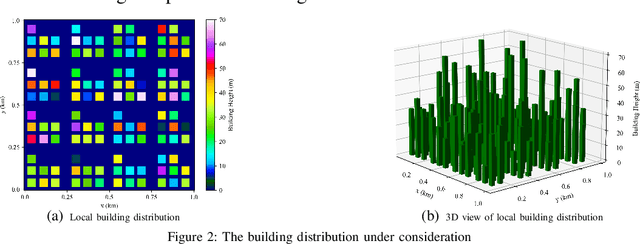

In cellular-connected unmanned aerial vehicle (UAV) network, a minimization problem on the weighted sum of time cost and expected outage duration is considered. Taking advantage of UAV's adjustable mobility, an intelligent UAV navigation approach is formulated to achieve the aforementioned optimization goal. Specifically, after mapping the navigation task into a Markov decision process (MDP), a deep reinforcement learning (DRL) solution with novel quantum-inspired experience replay (QiER) framework is proposed to help the UAV find the optimal flying direction within each time slot, and thus the designed trajectory towards the destination can be generated. Via relating experienced transition's importance to its associated quantum bit (qubit) and applying Grover iteration based amplitude amplification technique, the proposed DRL-QiER solution can commit a better trade-off between sampling priority and diversity. Compared to several representative baselines, the effectiveness and supremacy of the proposed DRL-QiER solution are demonstrated and validated in numerical results.
A Scalable Federated Multi-agent Architecture for Networked Connected Communication Network
Aug 01, 2021
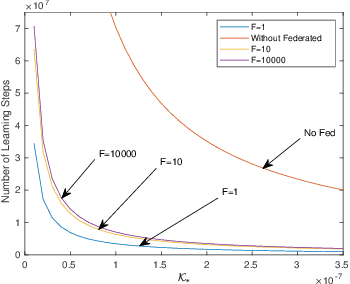
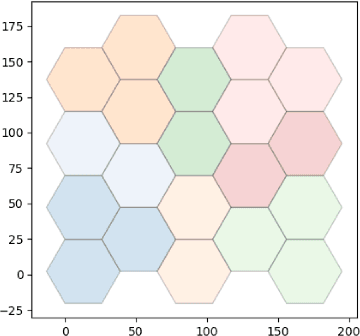
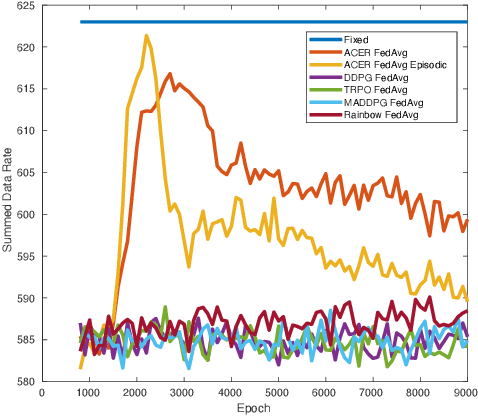
Scalability is the key roadstone towards the application of cooperative intelligent algorithms in large-scale networks. Reinforcement learning (RL) is known as model-free and high efficient intelligent algorithm for communication problems and proved useful in the communication network. However, when coming to large-scale networks with limited centralization, it is not possible to employ a centralized entity to perform joint real-time decision making for entire network. This introduces the scalability challenges, while multi-agent reinforcement shows the opportunity to cope this challenges and extend the intelligent algorithm to cooperative large-scale network. In this paper, we introduce the federated mean-field multi-agent reinforcement learning structure to capture the problem in large scale multi-agent communication scenarios, where agents share parameters to form consistency. We present the theoretical basis of our architecture and show the influence of federated frequency with an informational multi-agent model. We then exam the performance of our architecture with a coordinated multi-point environment which requires handshakes between neighbour access-points to realise the cooperation gain. Our result shows that the learning structure can effectively solve the cooperation problem in a large scale network with decent scalability. We also show the effectiveness of federated algorithms and highlight the importance of maintaining personality in each access-point.
Joint Resource Block and Beamforming Optimization for Cellular-Connected UAV Networks: A Hybrid D3QN-DDPG Approach
Feb 25, 2021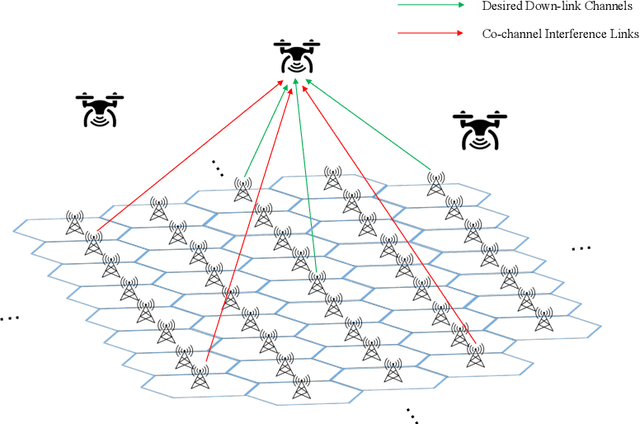
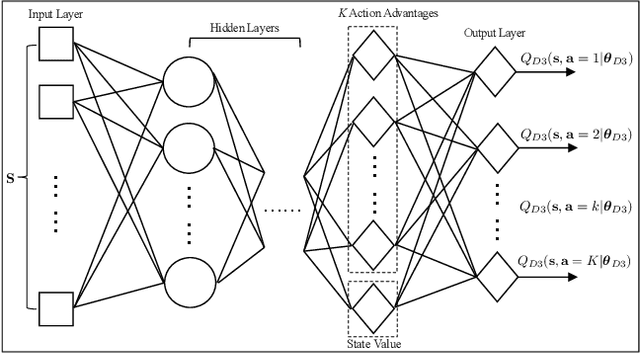
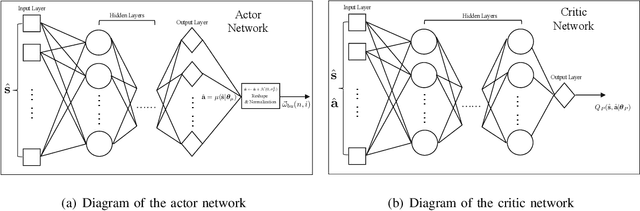
Integrating unmanned aerial vehicle (UAV) into the existing cellular networks that are delicately designed for terrestrial transmissions faces lots of challenges, in which one of the most striking concerns is how to adopt UAV into the cellular networks with less (or even without) adverse effects to ground users. In this paper, a cellular-connected UAV network is considered, in which multiple UAVs receive messages from terrestrial base stations (BSs) in the down-link, while BSs are serving ground users in their cells. Besides, the line-of-sight (LoS) wireless links are more likely to be established in ground-to-air (G2A) transmission scenarios. On one hand, UAVs may potentially get access to more BSs. On the other hand, more co-channel interferences could be involved. To enhance wireless transmission quality between UAVs and BSs while protecting the ground users from being interfered by the G2A communications, a joint time-frequency resource block (RB) and beamforming optimization problem is proposed and investigated in this paper. Specifically, with given flying trajectory, the ergodic outage duration (EOD) of UAV is minimized with the aid of RB resource allocation and beamforming design. Unfortunately, the proposed optimization problem is hard to be solved via standard optimization techniques, if not impossible. To crack this nut, a deep reinforcement learning (DRL) solution is proposed, where deep double duelling Q network (D3QN) and deep deterministic policy gradient (DDPG) are invoked to deal with RB allocation in discrete action domain and beamforming design in continuous action regime, respectively. The hybrid D3QN-DDPG solution is applied to solve the outer Markov decision process (MDP) and the inner MDP interactively so that it can achieve the sub-optimal result for the considered optimization problem.