 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay
Aug 30, 2021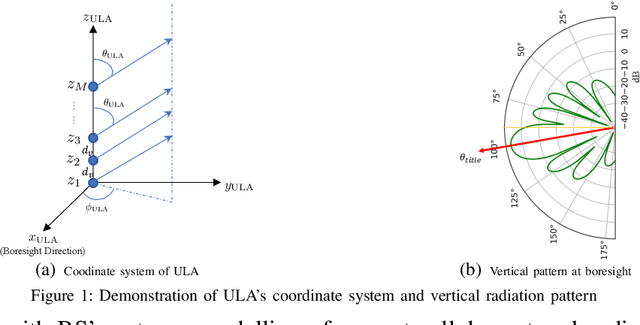

In cellular-connected unmanned aerial vehicle (UAV) network, a minimization problem on the weighted sum of time cost and expected outage duration is considered. Taking advantage of UAV's adjustable mobility, an intelligent UAV navigation approach is formulated to achieve the aforementioned optimization goal. Specifically, after mapping the navigation task into a Markov decision process (MDP), a deep reinforcement learning (DRL) solution with novel quantum-inspired experience replay (QiER) framework is proposed to help the UAV find the optimal flying direction within each time slot, and thus the designed trajectory towards the destination can be generated. Via relating experienced transition's importance to its associated quantum bit (qubit) and applying Grover iteration based amplitude amplification technique, the proposed DRL-QiER solution can commit a better trade-off between sampling priority and diversity. Compared to several representative baselines, the effectiveness and supremacy of the proposed DRL-QiER solution are demonstrated and validated in numerical results.
Joint Resource Block and Beamforming Optimization for Cellular-Connected UAV Networks: A Hybrid D3QN-DDPG Approach
Feb 25, 2021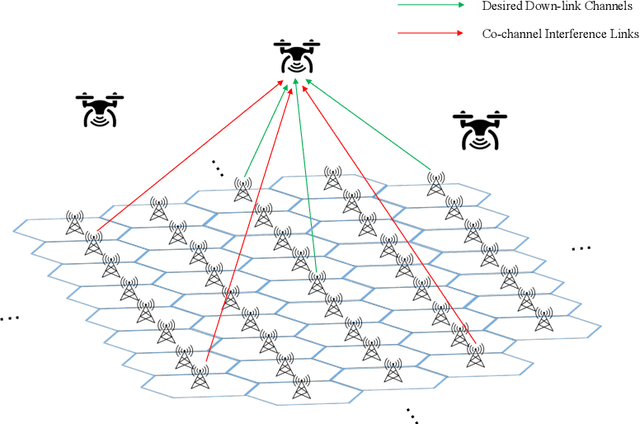
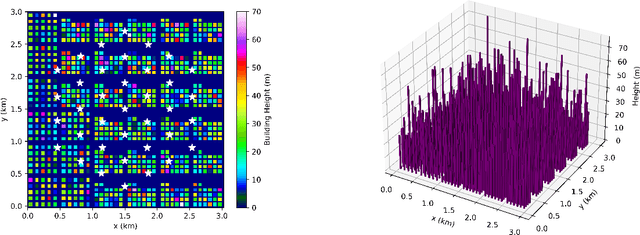
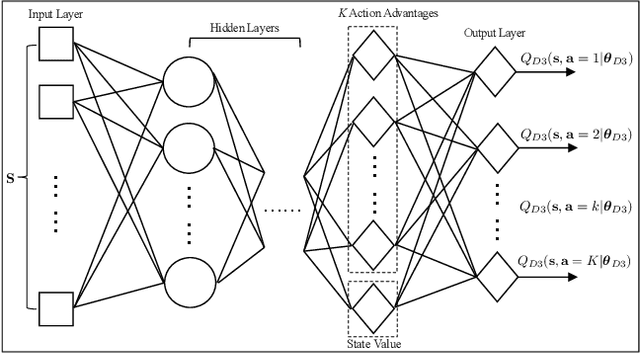
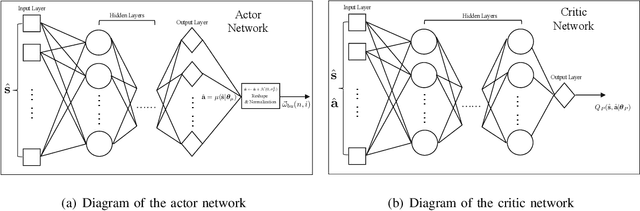
Integrating unmanned aerial vehicle (UAV) into the existing cellular networks that are delicately designed for terrestrial transmissions faces lots of challenges, in which one of the most striking concerns is how to adopt UAV into the cellular networks with less (or even without) adverse effects to ground users. In this paper, a cellular-connected UAV network is considered, in which multiple UAVs receive messages from terrestrial base stations (BSs) in the down-link, while BSs are serving ground users in their cells. Besides, the line-of-sight (LoS) wireless links are more likely to be established in ground-to-air (G2A) transmission scenarios. On one hand, UAVs may potentially get access to more BSs. On the other hand, more co-channel interferences could be involved. To enhance wireless transmission quality between UAVs and BSs while protecting the ground users from being interfered by the G2A communications, a joint time-frequency resource block (RB) and beamforming optimization problem is proposed and investigated in this paper. Specifically, with given flying trajectory, the ergodic outage duration (EOD) of UAV is minimized with the aid of RB resource allocation and beamforming design. Unfortunately, the proposed optimization problem is hard to be solved via standard optimization techniques, if not impossible. To crack this nut, a deep reinforcement learning (DRL) solution is proposed, where deep double duelling Q network (D3QN) and deep deterministic policy gradient (DDPG) are invoked to deal with RB allocation in discrete action domain and beamforming design in continuous action regime, respectively. The hybrid D3QN-DDPG solution is applied to solve the outer Markov decision process (MDP) and the inner MDP interactively so that it can achieve the sub-optimal result for the considered optimization problem.