 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUCAL: Jointly Calibrating Aleatoric and Epistemic Uncertainty in Classification Tasks
Feb 23, 2026We study post-calibration uncertainty for trained ensembles of classifiers. Specifically, we consider both aleatoric (label noise) and epistemic (model) uncertainty. Among the most popular and widely used calibration methods in classification are temperature scaling (i.e., pool-then-calibrate) and conformal methods. However, the main shortcoming of these calibration methods is that they do not balance the proportion of aleatoric and epistemic uncertainty. Not balancing these uncertainties can severely misrepresent predictive uncertainty, leading to overconfident predictions in some input regions while being underconfident in others. To address this shortcoming, we present a simple but powerful calibration algorithm Joint Uncertainty Calibration (JUCAL) that jointly calibrates aleatoric and epistemic uncertainty. JUCAL jointly calibrates two constants to weight and scale epistemic and aleatoric uncertainties by optimizing the negative log-likelihood (NLL) on the validation/calibration dataset. JUCAL can be applied to any trained ensemble of classifiers (e.g., transformers, CNNs, or tree-based methods), with minimal computational overhead, without requiring access to the models' internal parameters. We experimentally evaluate JUCAL on various text classification tasks, for ensembles of varying sizes and with different ensembling strategies. Our experiments show that JUCAL significantly outperforms SOTA calibration methods across all considered classification tasks, reducing NLL and predictive set size by up to 15% and 20%, respectively. Interestingly, even applying JUCAL to an ensemble of size 5 can outperform temperature-scaled ensembles of size up to 50 in terms of NLL and predictive set size, resulting in up to 10 times smaller inference costs. Thus, we propose JUCAL as a new go-to method for calibrating ensembles in classification.
Robust pricing and hedging via neural SDEs
Jul 08, 2020

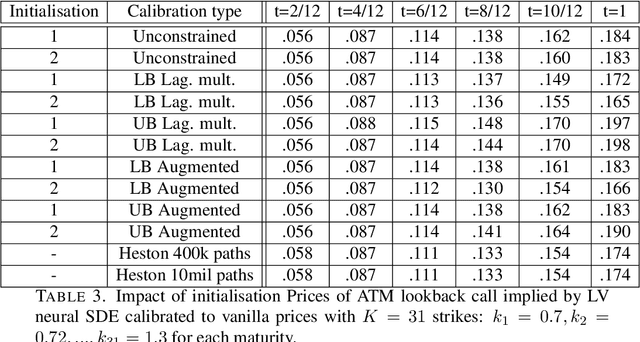
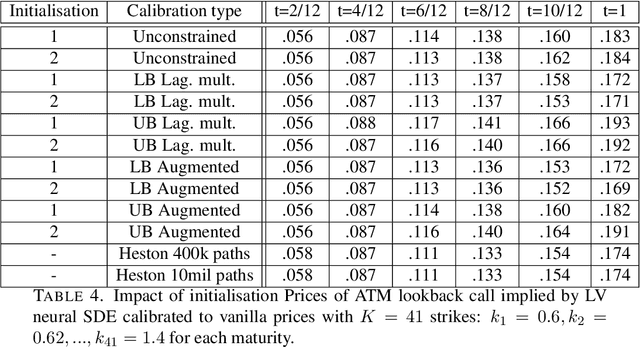
Mathematical modelling is ubiquitous in the financial industry and drives key decision processes. Any given model provides only a crude approximation to reality and the risk of using an inadequate model is hard to detect and quantify. By contrast, modern data science techniques are opening the door to more robust and data-driven model selection mechanisms. However, most machine learning models are "black-boxes" as individual parameters do not have meaningful interpretation. The aim of this paper is to combine the above approaches achieving the best of both worlds. Combining neural networks with risk models based on classical stochastic differential equations (SDEs), we find robust bounds for prices of derivatives and the corresponding hedging strategies while incorporating relevant market data. The resulting model called neural SDE is an instantiation of generative models and is closely linked with the theory of causal optimal transport. Neural SDEs allow consistent calibration under both the risk-neutral and the real-world measures. Thus the model can be used to simulate market scenarios needed for assessing risk profiles and hedging strategies. We develop and analyse novel algorithms needed for efficient use of neural SDEs. We validate our approach with numerical experiments using both local and stochastic volatility models.