 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWORD: Revisiting Organs Segmentation in the Whole Abdominal Region
Paper and Code


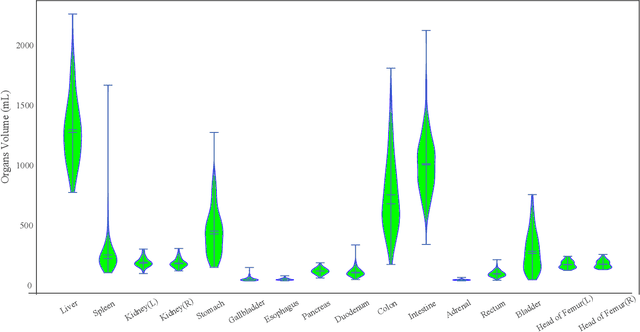

Whole abdominal organs segmentation plays an important role in abdomen lesion diagnosis, radiotherapy planning, and follow-up. However, delineating all abdominal organs by oncologists manually is time-consuming and very expensive. Recently, deep learning-based medical image segmentation has shown the potential to reduce manual delineation efforts, but it still requires a large-scale fine annotated dataset for training. Although many efforts in this task, there are still few large image datasets covering the whole abdomen region with accurate and detailed annotations for the whole abdominal organ segmentation. In this work, we establish a large-scale \textit{W}hole abdominal \textit{OR}gans \textit{D}ataset (\textit{WORD}) for algorithms research and clinical applications development. This dataset contains 150 abdominal CT volumes (30495 slices) and each volume has 16 organs with fine pixel-level annotations and scribble-based sparse annotation, which may be the largest dataset with whole abdominal organs annotation. Several state-of-the-art segmentation methods are evaluated on this dataset. And, we also invited clinical oncologists to revise the model predictions to measure the gap between the deep learning method and real oncologists. We further introduce and evaluate a new scribble-based weakly supervised segmentation on this dataset. The work provided a new benchmark for the abdominal multi-organ segmentation task and these experiments can serve as the baseline for future research and clinical application development. The codebase and dataset will be released at: https://github.com/HiLab-git/WORD