 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisper-KDQ: A Lightweight Whisper via Guided Knowledge Distillation and Quantization for Efficient ASR
Paper and Code
May 18, 2023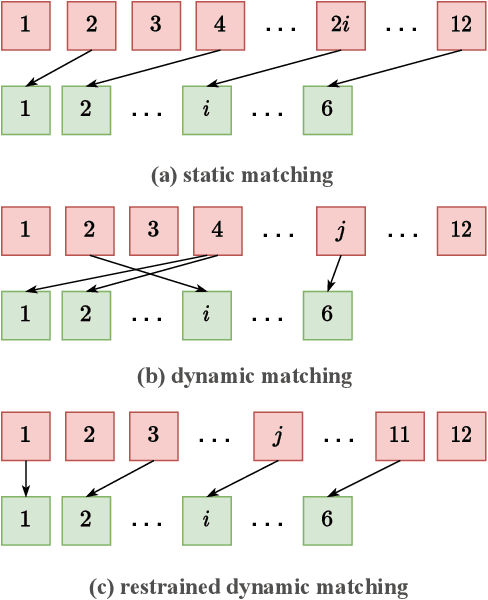
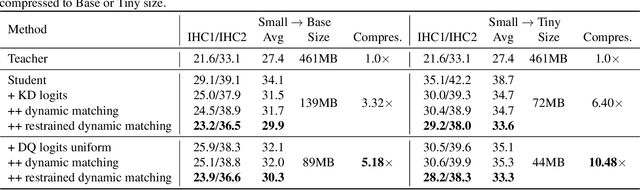
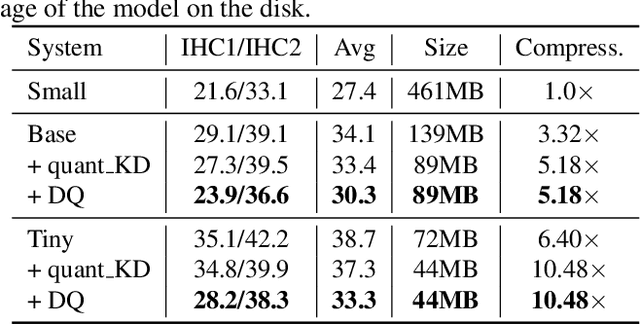
Due to the rapid development of computing hardware resources and the dramatic growth of data, pre-trained models in speech recognition, such as Whisper, have significantly improved the performance of speech recognition tasks. However, these models usually have a high computational overhead, making it difficult to execute effectively on resource-constrained devices. To speed up inference and reduce model size while maintaining performance, we propose a novel guided knowledge distillation and quantization for large pre-trained model Whisper. The student model selects distillation and quantization layers based on quantization loss and distillation loss, respectively. We compressed $\text{Whisper}_\text{small}$ to $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$ levels, making $\text{Whisper}_\text{small}$ 5.18x/10.48x smaller, respectively. Moreover, compared to the original $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$, there is also a relative character error rate~(CER) reduction of 11.3% and 14.0% for the new compressed model respectively.