 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes RAFT Better Than PWC-Net?
Paper and Code

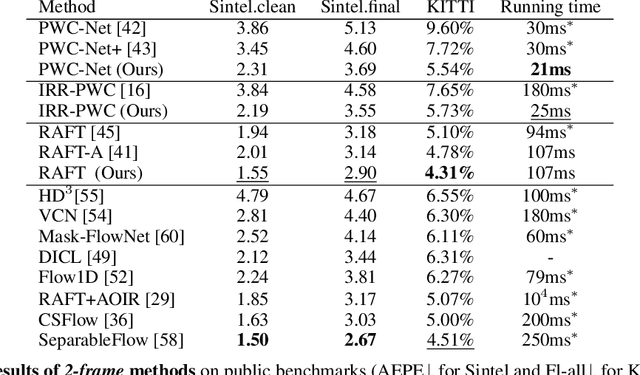

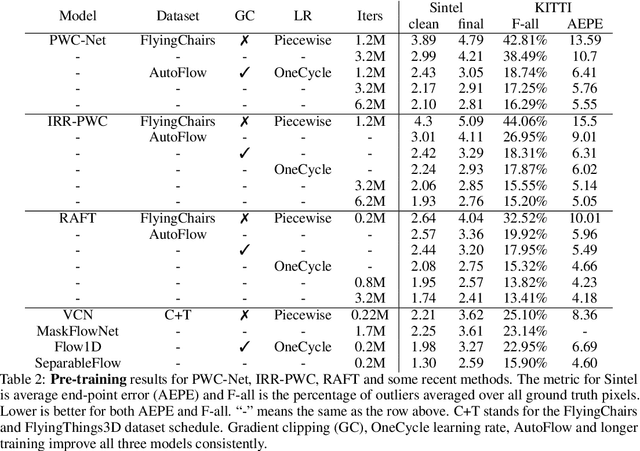
How important are training details and datasets to recent optical flow models like RAFT? And do they generalize? To explore these questions, rather than develop a new model, we revisit three prominent models, PWC-Net, IRR-PWC and RAFT, with a common set of modern training techniques and datasets, and observe significant performance gains, demonstrating the importance and generality of these training details. Our newly trained PWC-Net and IRR-PWC models show surprisingly large improvements, up to 30% versus original published results on Sintel and KITTI 2015 benchmarks. They outperform the more recent Flow1D on KITTI 2015 while being 3x faster during inference. Our newly trained RAFT achieves an Fl-all score of 4.31% on KITTI 2015, more accurate than all published optical flow methods at the time of writing. Our results demonstrate the benefits of separating the contributions of models, training techniques and datasets when analyzing performance gains of optical flow methods. Our source code will be publicly available.