 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks
Paper and Code


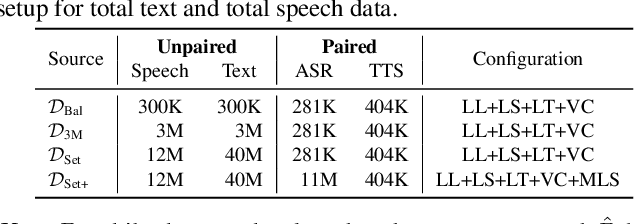

We propose a decoder-only language model, \textit{VoxtLM}, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90. VoxtLM also improves speech generation and speech recognition performance over the single-task counterpart. VoxtLM is trained with publicly available data and training recipes and model checkpoints will be open-sourced to make fully reproducible work.