 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice-Face Homogeneity Tells Deepfake
Paper and Code

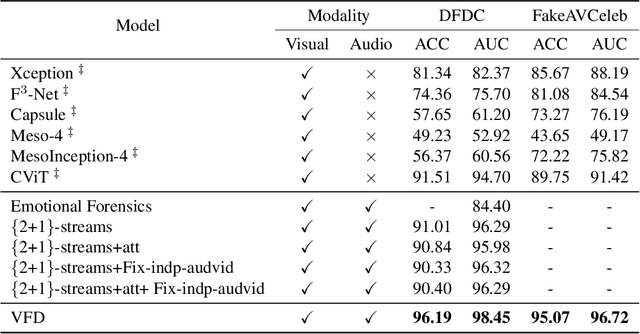
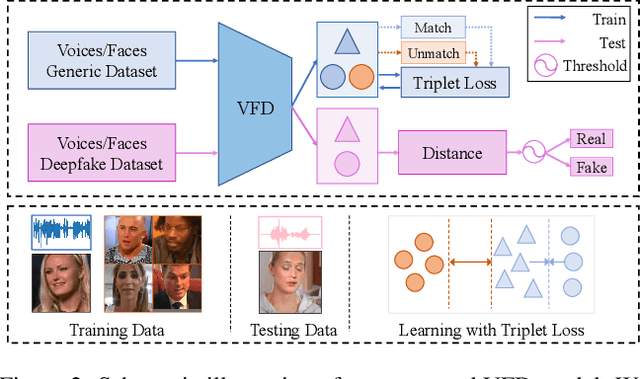
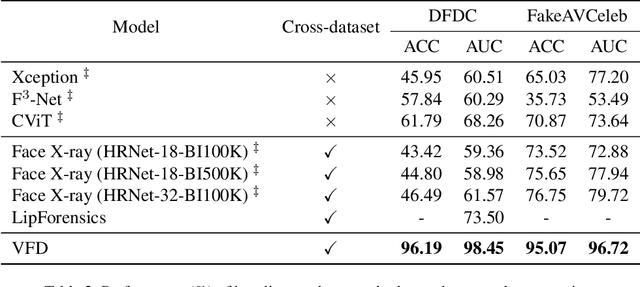
Detecting forgery videos is highly desired due to the abuse of deepfake. Existing detection approaches contribute to exploring the specific artifacts in deepfake videos and fit well on certain data. However, the growing technique on these artifacts keeps challenging the robustness of traditional deepfake detectors. As a result, the development of generalizability of these approaches has reached a blockage. To address this issue, given the empirical results that the identities behind voices and faces are often mismatched in deepfake videos, and the voices and faces have homogeneity to some extent, in this paper, we propose to perform the deepfake detection from an unexplored voice-face matching view. To this end, a voice-face matching detection model is devised to measure the matching degree of these two on a generic audio-visual dataset. Thereafter, this model can be smoothly transferred to deepfake datasets without any fine-tuning, and the generalization across datasets is accordingly enhanced. We conduct extensive experiments over two widely exploited datasets - DFDC and FakeAVCeleb. Our model obtains significantly improved performance as compared to other state-of-the-art competitors and maintains favorable generalizability. The code has been released at https://github.com/xaCheng1996/VFD.