 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-Lens: Towards Omni-modal Representations
Paper and Code
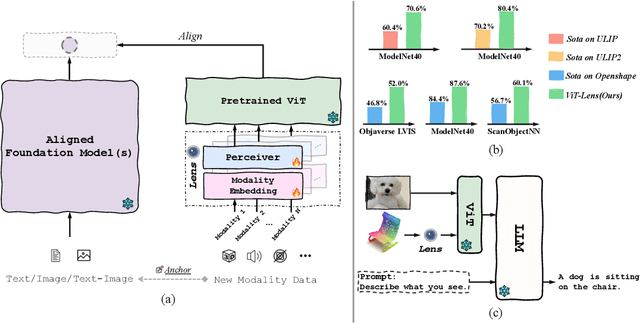
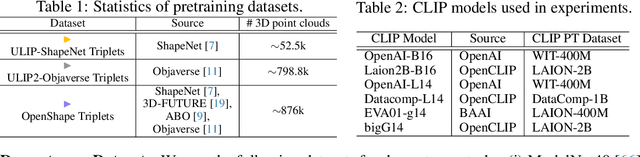
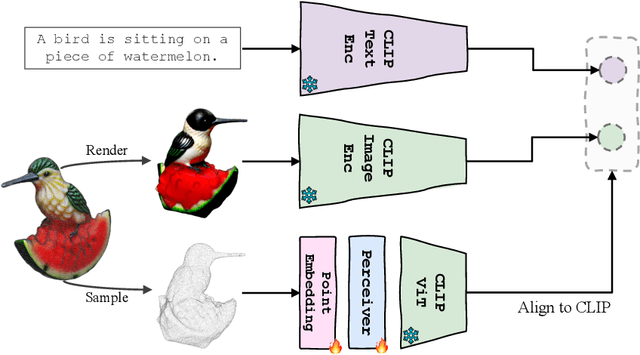
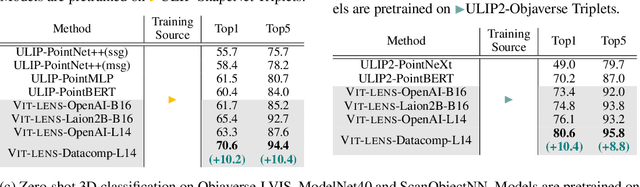
Though the success of CLIP-based training recipes in vision-language models, their scalability to more modalities (e.g., 3D, audio, etc.) is limited to large-scale data, which is expensive or even inapplicable for rare modalities. In this paper, we present ViT-Lens that facilitates efficient omni-modal representation learning by perceiving novel modalities with a pretrained ViT and aligning to a pre-defined space. Specifically, the modality-specific lens is tuned to project multimodal signals to the shared embedding space, which are then processed by a strong ViT that carries pre-trained image knowledge. The encoded multimodal representations are optimized toward aligning with the modal-independent space, pre-defined by off-the-shelf foundation models. A well-trained lens with a ViT backbone has the potential to serve as one of these foundation models, supervising the learning of subsequent modalities. ViT-Lens provides a unified solution for representation learning of increasing modalities with two appealing benefits: (i) Exploiting the pretrained ViT across tasks and domains effectively with efficient data regime; (ii) Emergent downstream capabilities of novel modalities are demonstrated due to the modality alignment space. We evaluate ViT-Lens in the context of 3D as an initial verification. In zero-shot 3D classification, ViT-Lens achieves substantial improvements over previous state-of-the-art, showing 52.0% accuracy on Objaverse-LVIS, 87.4% on ModelNet40, and 60.6% on ScanObjectNN. Furthermore, we enable zero-shot 3D question-answering by simply integrating the trained 3D lens into the InstructBLIP model without any adaptation. We will release the results of ViT-Lens on more modalities in the near future.