 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Commonsense-aware Representation Network for Video Captioning
Paper and Code
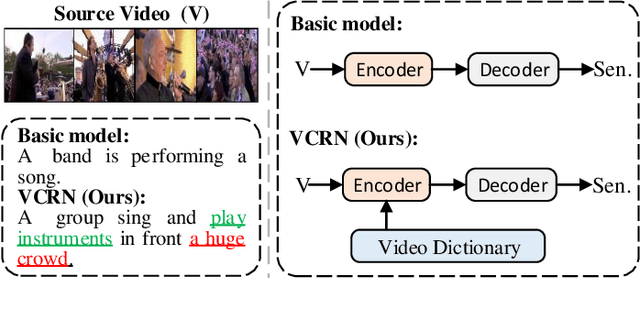
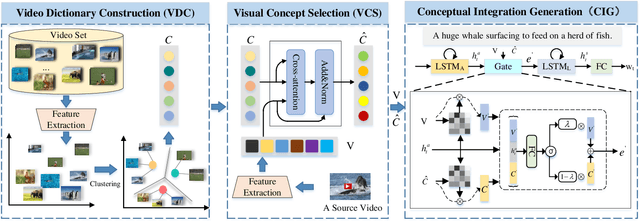
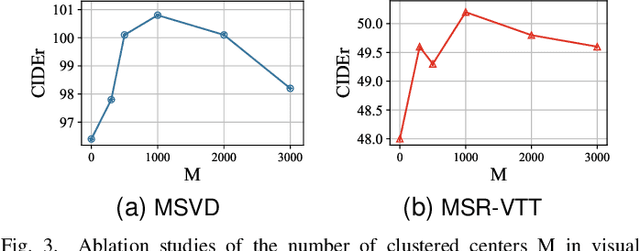
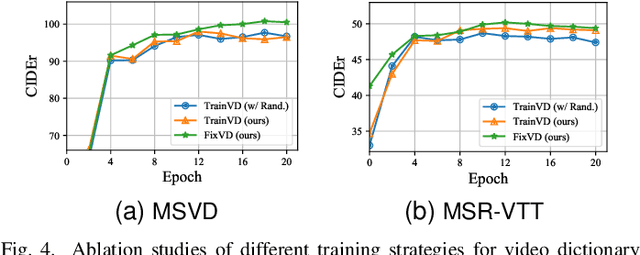
Generating consecutive descriptions for videos, i.e., Video Captioning, requires taking full advantage of visual representation along with the generation process. Existing video captioning methods focus on making an exploration of spatial-temporal representations and their relationships to produce inferences. However, such methods only exploit the superficial association contained in the video itself without considering the intrinsic visual commonsense knowledge that existed in a video dataset, which may hinder their capabilities of knowledge cognitive to reason accurate descriptions. To address this problem, we propose a simple yet effective method, called Visual Commonsense-aware Representation Network (VCRN), for video captioning. Specifically, we construct a Video Dictionary, a plug-and-play component, obtained by clustering all video features from the total dataset into multiple clustered centers without additional annotation. Each center implicitly represents a visual commonsense concept in the video domain, which is utilized in our proposed Visual Concept Selection (VCS) to obtain a video-related concept feature. Next, a Conceptual Integration Generation (CIG) is proposed to enhance the caption generation. Extensive experiments on three publicly video captioning benchmarks: MSVD, MSR-VTT, and VATEX, demonstrate that our method reaches state-of-the-art performance, indicating the effectiveness of our method. In addition, our approach is integrated into the existing method of video question answering and improves this performance, further showing the generalization of our method. Source code has been released at https://github.com/zchoi/VCRN.