 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Meets the Skeleton: Progressively Distillation with Cross-Modal Knowledge for 3D Action Representation Learning
Paper and Code
May 31, 2024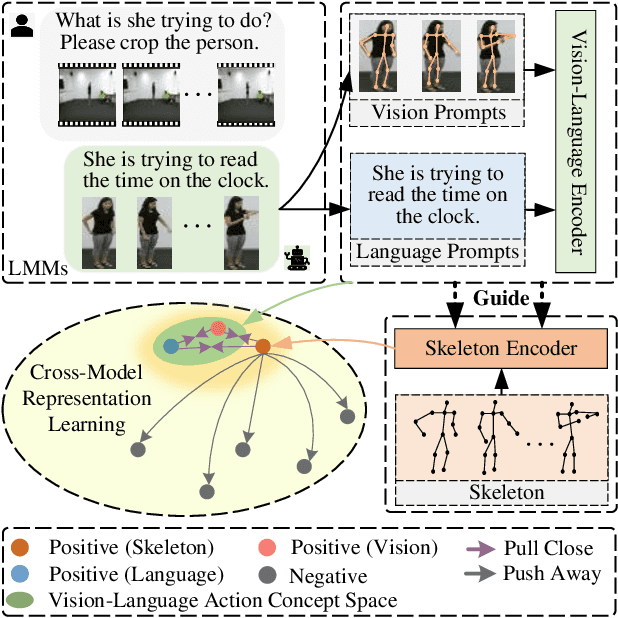



Supervised and self-supervised learning are two main training paradigms for skeleton-based human action recognition. However, the former one-hot classification requires labor-intensive predefined action categories annotations, while the latter involves skeleton transformations (e.g., cropping) in the pretext tasks that may impair the skeleton structure. To address these challenges, we introduce a novel skeleton-based training framework (C$^2$VL) based on Cross-modal Contrastive learning that uses the progressive distillation to learn task-agnostic human skeleton action representation from the Vision-Language knowledge prompts. Specifically, we establish the vision-language action concept space through vision-language knowledge prompts generated by pre-trained large multimodal models (LMMs), which enrich the fine-grained details that the skeleton action space lacks. Moreover, we propose the intra-modal self-similarity and inter-modal cross-consistency softened targets in the cross-modal contrastive process to progressively control and guide the degree of pulling vision-language knowledge prompts and corresponding skeletons closer. These soft instance discrimination and self-knowledge distillation strategies contribute to the learning of better skeleton-based action representations from the noisy skeleton-vision-language pairs. During the inference phase, our method requires only the skeleton data as the input for action recognition and no longer for vision-language prompts. Extensive experiments show that our method achieves state-of-the-art results on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets. The code will be available in the future.