 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Field Attention for Deformable Image Registration
Paper and Code
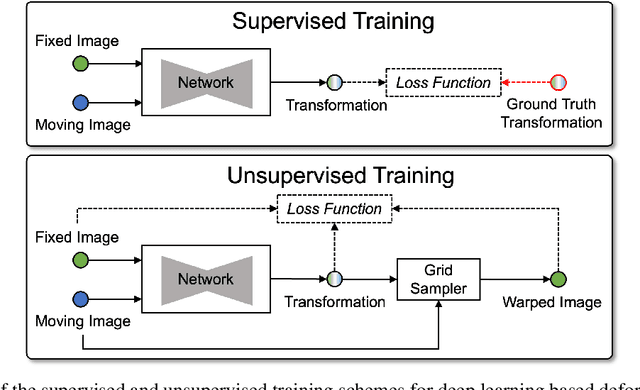



Deformable image registration establishes non-linear spatial correspondences between fixed and moving images. Deep learning-based deformable registration methods have been widely studied in recent years due to their speed advantage over traditional algorithms as well as their better accuracy. Most existing deep learning-based methods require neural networks to encode location information in their feature maps and predict displacement or deformation fields though convolutional or fully connected layers from these high-dimensional feature maps. In this work, we present Vector Field Attention (VFA), a novel framework that enhances the efficiency of the existing network design by enabling direct retrieval of location correspondences. VFA uses neural networks to extract multi-resolution feature maps from the fixed and moving images and then retrieves pixel-level correspondences based on feature similarity. The retrieval is achieved with a novel attention module without the need of learnable parameters. VFA is trained end-to-end in either a supervised or unsupervised manner. We evaluated VFA for intra- and inter-modality registration and for unsupervised and semi-supervised registration using public datasets, and we also evaluated it on the Learn2Reg challenge. Experimental results demonstrate the superior performance of VFA compared to existing methods. The source code of VFA is publicly available at https://github.com/yihao6/vfa/.