 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCSUM: A Versatile Chinese Meeting Summarization Dataset
Paper and Code

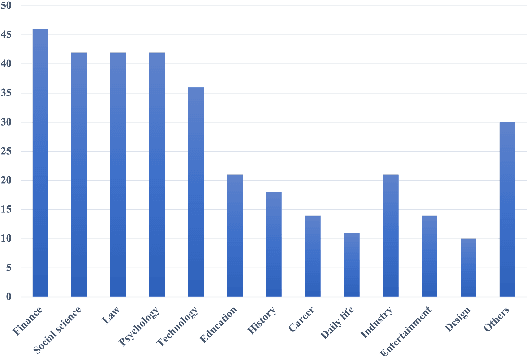
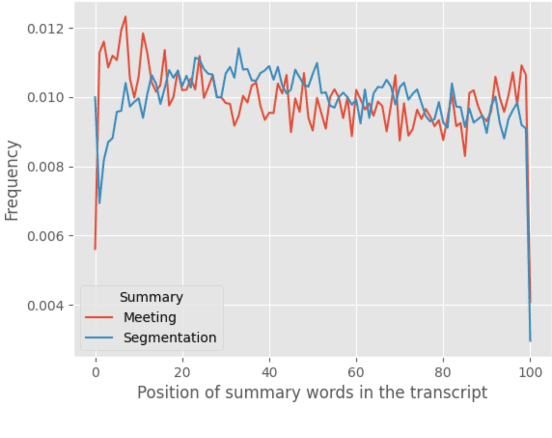
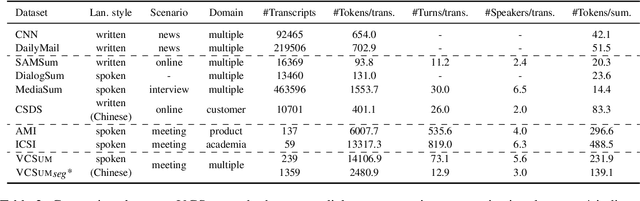
Compared to news and chat summarization, the development of meeting summarization is hugely decelerated by the limited data. To this end, we introduce a versatile Chinese meeting summarization dataset, dubbed VCSum, consisting of 239 real-life meetings, with a total duration of over 230 hours. We claim our dataset is versatile because we provide the annotations of topic segmentation, headlines, segmentation summaries, overall meeting summaries, and salient sentences for each meeting transcript. As such, the dataset can adapt to various summarization tasks or methods, including segmentation-based summarization, multi-granularity summarization and retrieval-then-generate summarization. Our analysis confirms the effectiveness and robustness of VCSum. We also provide a set of benchmark models regarding different downstream summarization tasks on VCSum to facilitate further research. The dataset and code will be released at https://github.com/hahahawu/VCSum.