 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Reduction in Training Forecasting Models with Subgroup Sampling
Paper and Code
Mar 02, 2021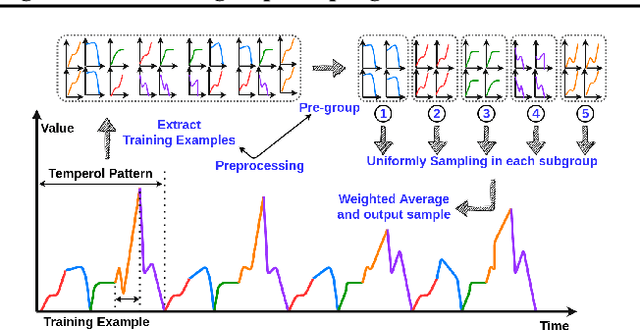
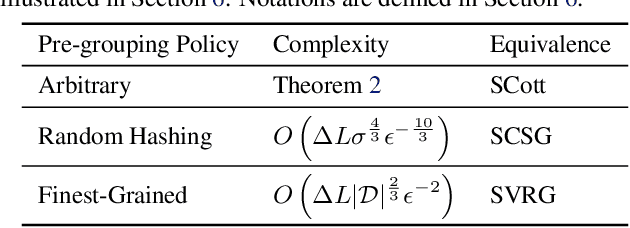
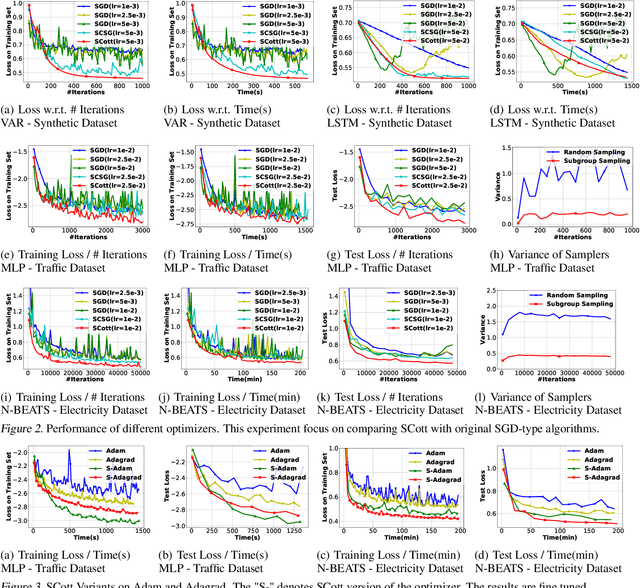
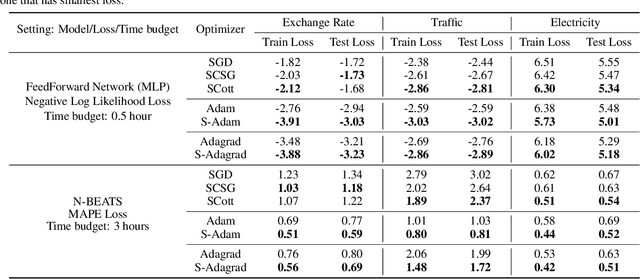
In real-world applications of large-scale time series, one often encounters the situation where the temporal patterns of time series, while drifting over time, differ from one another in the same dataset. In this paper, we provably show under such heterogeneity, training a forecasting model with commonly used stochastic optimizers (e.g. SGD) potentially suffers large gradient variance, and thus requires long time training. To alleviate this issue, we propose a sampling strategy named Subgroup Sampling, which mitigates the large variance via sampling over pre-grouped time series. We further introduce SCott, a variance reduced SGD-style optimizer that co-designs subgroup sampling with the control variate method. In theory, we provide the convergence guarantee of SCott on smooth non-convex objectives. Empirically, we evaluate SCott and other baseline optimizers on both synthetic and real-world time series forecasting problems, and show SCott converges faster with respect to both iterations and wall clock time. Additionally, we show two SCott variants that can speed up Adam and Adagrad without compromising generalization of forecasting models.