 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLearn: Enhancing Dynamic Facial Expression Recognition through Unified Pre-Training and Fine-Tuning on Images and Videos
Paper and Code
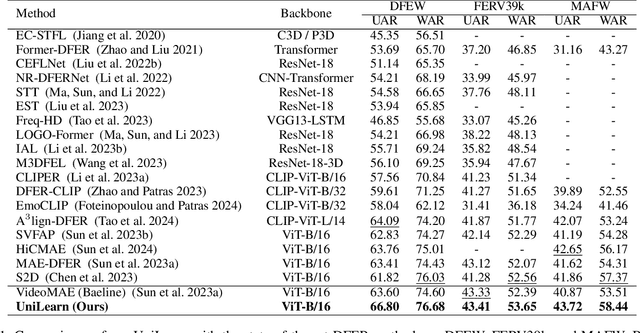
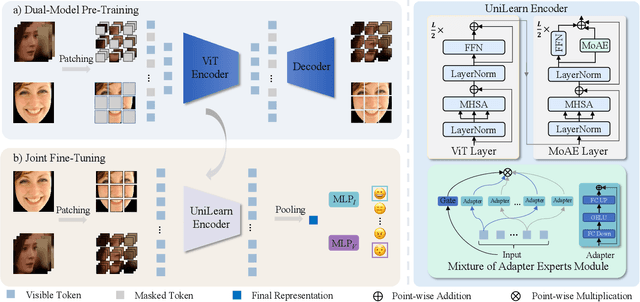

Dynamic facial expression recognition (DFER) is essential for understanding human emotions and behavior. However, conventional DFER methods, which primarily use dynamic facial data, often underutilize static expression images and their labels, limiting their performance and robustness. To overcome this, we introduce UniLearn, a novel unified learning paradigm that integrates static facial expression recognition (SFER) data to enhance DFER task. UniLearn employs a dual-modal self-supervised pre-training method, leveraging both facial expression images and videos to enhance a ViT model's spatiotemporal representation capability. Then, the pre-trained model is fine-tuned on both static and dynamic expression datasets using a joint fine-tuning strategy. To prevent negative transfer during joint fine-tuning, we introduce an innovative Mixture of Adapter Experts (MoAE) module that enables task-specific knowledge acquisition and effectively integrates information from both static and dynamic expression data. Extensive experiments demonstrate UniLearn's effectiveness in leveraging complementary information from static and dynamic facial data, leading to more accurate and robust DFER. UniLearn consistently achieves state-of-the-art performance on FERV39K, MAFW, and DFEW benchmarks, with weighted average recall (WAR) of 53.65\%, 58.44\%, and 76.68\%, respectively. The source code and model weights will be publicly available at \url{https://github.com/MSA-LMC/UniLearn}.