 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Field Theory for Deep and Recurrent Neural Networks
Paper and Code
Jan 07, 2022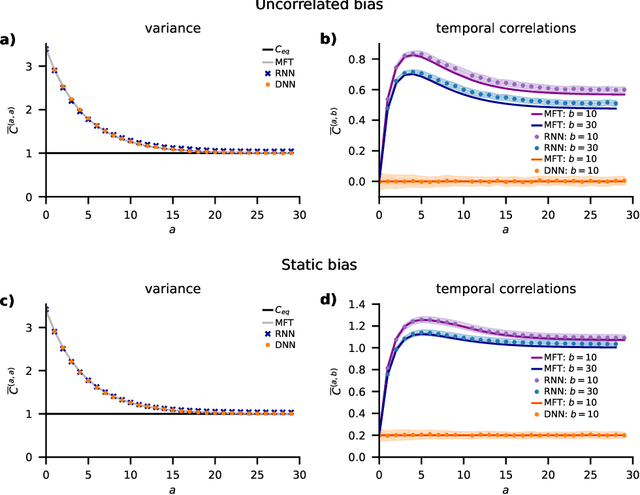
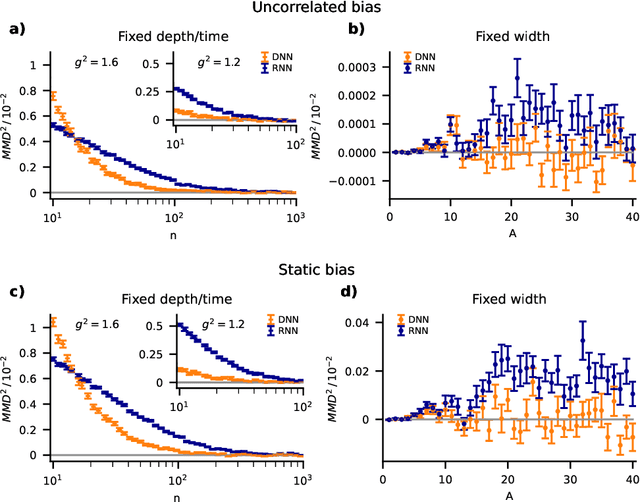
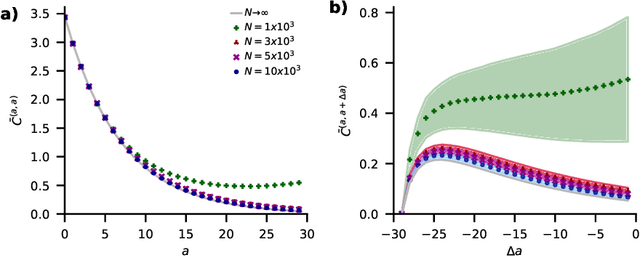
Understanding capabilities and limitations of different network architectures is of fundamental importance to machine learning. Bayesian inference on Gaussian processes has proven to be a viable approach for studying recurrent and deep networks in the limit of infinite layer width, $n\to\infty$. Here we present a unified and systematic derivation of the mean-field theory for both architectures that starts from first principles by employing established methods from statistical physics of disordered systems. The theory elucidates that while the mean-field equations are different with regard to their temporal structure, they yet yield identical Gaussian kernels when readouts are taken at a single time point or layer, respectively. Bayesian inference applied to classification then predicts identical performance and capabilities for the two architectures. Numerically, we find that convergence towards the mean-field theory is typically slower for recurrent networks than for deep networks and the convergence speed depends non-trivially on the parameters of the weight prior as well as the depth or number of time steps, respectively. Our method exposes that Gaussian processes are but the lowest order of a systematic expansion in $1/n$. The formalism thus paves the way to investigate the fundamental differences between recurrent and deep architectures at finite widths $n$.