 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Cross-Modal Image Synthesis with Hierarchical Mixture of Product-of-Experts
Paper and Code
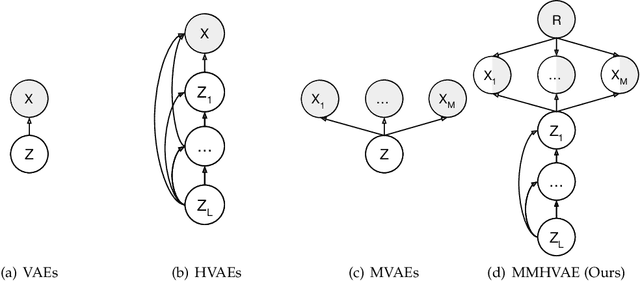



We propose a deep mixture of multimodal hierarchical variational auto-encoders called MMHVAE that synthesizes missing images from observed images in different modalities. MMHVAE's design focuses on tackling four challenges: (i) creating a complex latent representation of multimodal data to generate high-resolution images; (ii) encouraging the variational distributions to estimate the missing information needed for cross-modal image synthesis; (iii) learning to fuse multimodal information in the context of missing data; (iv) leveraging dataset-level information to handle incomplete data sets at training time. Extensive experiments are performed on the challenging problem of pre-operative brain multi-parametric magnetic resonance and intra-operative ultrasound imaging.