 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-AdaFocus: Spatial-temporal Dynamic Computation for Video Recognition
Paper and Code


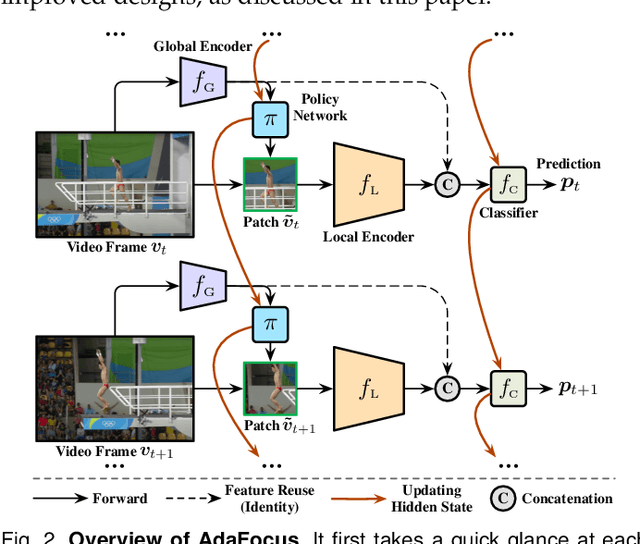

This paper presents a comprehensive exploration of the phenomenon of data redundancy in video understanding, with the aim to improve computational efficiency. Our investigation commences with an examination of spatial redundancy, which refers to the observation that the most informative region in each video frame usually corresponds to a small image patch, whose shape, size and location shift smoothly across frames. Motivated by this phenomenon, we formulate the patch localization problem as a dynamic decision task, and introduce a spatially adaptive video recognition approach, termed AdaFocus. In specific, a lightweight encoder is first employed to quickly process the full video sequence, whose features are then utilized by a policy network to identify the most task-relevant regions. Subsequently, the selected patches are inferred by a high-capacity deep network for the final prediction. The full model can be trained in end-to-end conveniently. Furthermore, AdaFocus can be extended by further considering temporal and sample-wise redundancies, i.e., allocating the majority of computation to the most task-relevant frames, and minimizing the computation spent on relatively "easier" videos. Our resulting approach, Uni-AdaFocus, establishes a comprehensive framework that seamlessly integrates spatial, temporal, and sample-wise dynamic computation, while it preserves the merits of AdaFocus in terms of efficient end-to-end training and hardware friendliness. In addition, Uni-AdaFocus is general and flexible as it is compatible with off-the-shelf efficient backbones (e.g., TSM and X3D), which can be readily deployed as our feature extractor, yielding a significantly improved computational efficiency. Empirically, extensive experiments based on seven benchmark datasets and three application scenarios substantiate that Uni-AdaFocus is considerably more efficient than the competitive baselines.