 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Training-free Diffusion Guidance: Mechanisms and Limitations
Paper and Code

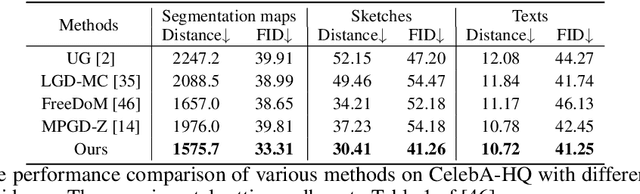


Adding additional control to pretrained diffusion models has become an increasingly popular research area, with extensive applications in computer vision, reinforcement learning, and AI for science. Recently, several studies have proposed training-free diffusion guidance by using off-the-shelf networks pretrained on clean images. This approach enables zero-shot conditional generation for universal control formats, which appears to offer a free lunch in diffusion guidance. In this paper, we aim to develop a deeper understanding of the operational mechanisms and fundamental limitations of training-free guidance. We offer a theoretical analysis that supports training-free guidance from the perspective of optimization, distinguishing it from classifier-based (or classifier-free) guidance. To elucidate their drawbacks, we theoretically demonstrate that training-free methods are more susceptible to adversarial gradients and exhibit slower convergence rates compared to classifier guidance. We then introduce a collection of techniques designed to overcome the limitations, accompanied by theoretical rationale and empirical evidence. Our experiments in image and motion generation confirm the efficacy of these techniques.