 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Learning Dynamics for Neural Machine Translation
Paper and Code
Apr 05, 2020

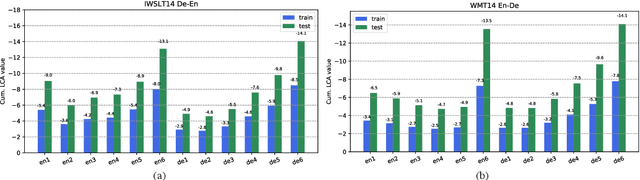
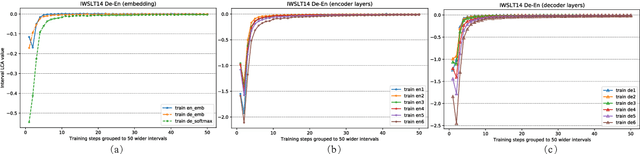
Despite the great success of NMT, there still remains a severe challenge: it is hard to interpret the internal dynamics during its training process. In this paper we propose to understand learning dynamics of NMT by using a recent proposed technique named Loss Change Allocation (LCA)~\citep{lan-2019-loss-change-allocation}. As LCA requires calculating the gradient on an entire dataset for each update, we instead present an approximate to put it into practice in NMT scenario. %motivated by the lesson from sgd. Our simulated experiment shows that such approximate calculation is efficient and is empirically proved to deliver consistent results to the brute-force implementation. In particular, extensive experiments on two standard translation benchmark datasets reveal some valuable findings.