 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Optimizing Deep Learning Cold-Start Latency on Edge Devices
Paper and Code
Jun 15, 2022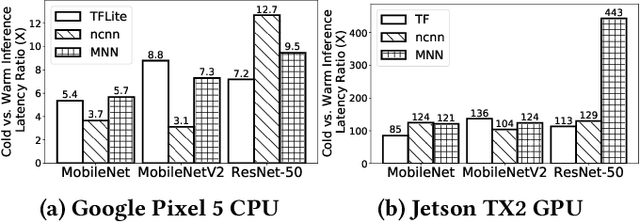



DNNs are ubiquitous on edge devices nowadays. With its increasing importance and use cases, it's not likely to pack all DNNs into device memory and expect that each inference has been warmed up. Therefore, cold inference, the process to read, initialize, and execute a DNN model, is becoming commonplace and its performance is urgently demanded to be optimized. To this end, we present NNV12, the first on-device inference engine that optimizes for cold inference NNV12 is built atop 3 novel optimization knobs: selecting a proper kernel (implementation) for each DNN operator, bypassing the weights transformation process by caching the post-transformed weights on disk, and pipelined execution of many kernels on asymmetric processors. To tackle with the huge search space, NNV12 employs a heuristic-based scheme to obtain a near-optimal kernel scheduling plan. We fully implement a prototype of NNV12 and evaluate its performance across extensive experiments. It shows that NNV12 achieves up to 15.2x and 401.5x compared to the state-of-the-art DNN engines on edge CPUs and GPUs, respectively.