Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Aspect Information Fusion Model For ABAW4 Multi-task Challenge
Paper and Code
Jul 23, 2022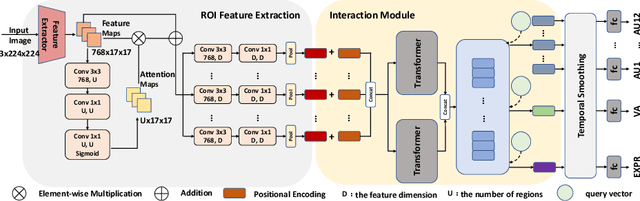
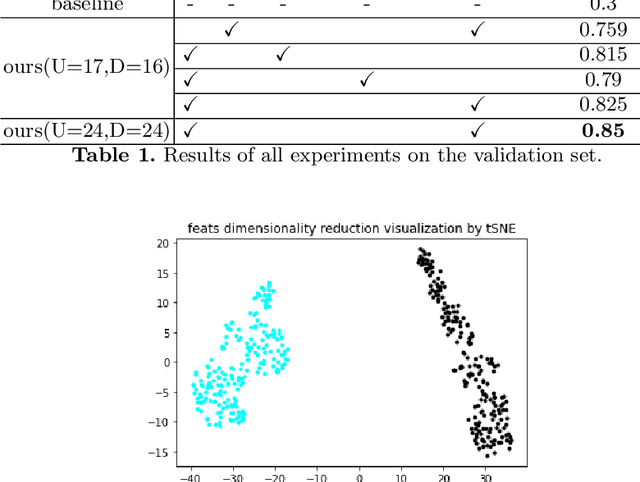

In this paper, we propose the solution to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. The task of ABAW is to predict frame-level emotion descriptors from videos: discrete emotional state; valence and arousal; and action units. Although researchers have proposed several approaches and achieved promising results in ABAW, current works in this task rarely consider interactions between different emotion descriptors. To this end, we propose a novel end to end architecture to achieve full integration of different types of information. Experimental results demonstrate the effectiveness of our proposed solution.
View paper on