 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune it the Right Way: Unsupervised Validation of Domain Adaptation via Soft Neighborhood Density
Paper and Code


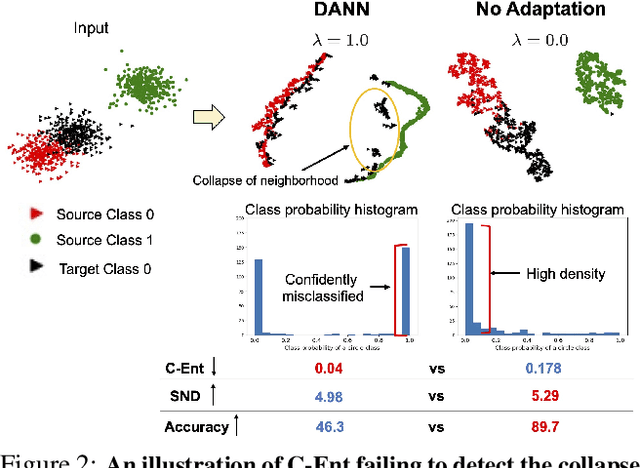

Unsupervised domain adaptation (UDA) methods can dramatically improve generalization on unlabeled target domains. However, optimal hyper-parameter selection is critical to achieving high accuracy and avoiding negative transfer. Supervised hyper-parameter validation is not possible without labeled target data, which raises the question: How can we validate unsupervised adaptation techniques in a realistic way? We first empirically analyze existing criteria and demonstrate that they are not very effective for tuning hyper-parameters. Intuitively, a well-trained source classifier should embed target samples of the same class nearby, forming dense neighborhoods in feature space. Based on this assumption, we propose a novel unsupervised validation criterion that measures the density of soft neighborhoods by computing the entropy of the similarity distribution between points. Our criterion is simpler than competing validation methods, yet more effective; it can tune hyper-parameters and the number of training iterations in both image classification and semantic segmentation models. The code used for the paper will be available at \url{https://github.com/VisionLearningGroup/SND}.