 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransMOT: Spatial-Temporal Graph Transformer for Multiple Object Tracking
Paper and Code
Apr 03, 2021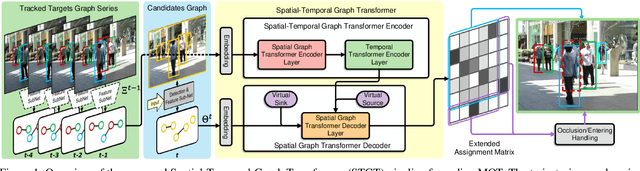
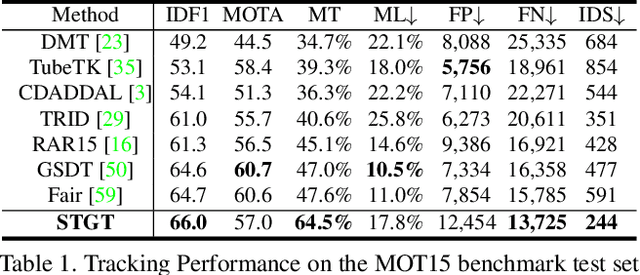
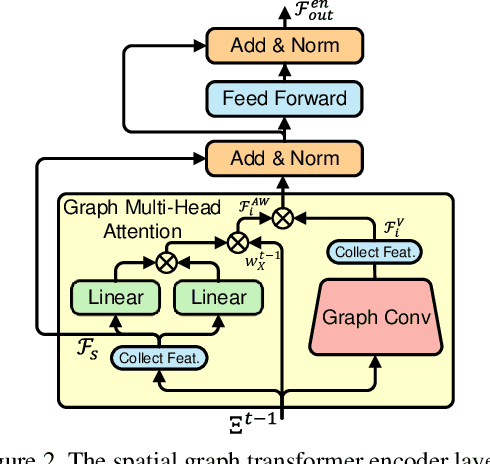
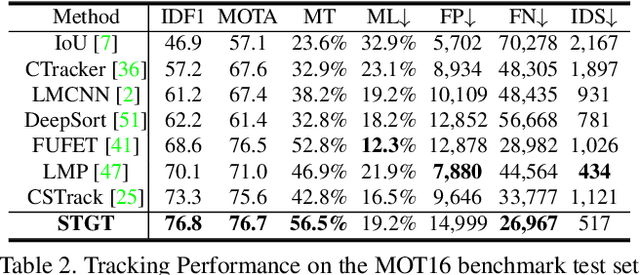
Tracking multiple objects in videos relies on modeling the spatial-temporal interactions of the objects. In this paper, we propose a solution named TransMOT, which leverages powerful graph transformers to efficiently model the spatial and temporal interactions among the objects. TransMOT effectively models the interactions of a large number of objects by arranging the trajectories of the tracked objects as a set of sparse weighted graphs, and constructing a spatial graph transformer encoder layer, a temporal transformer encoder layer, and a spatial graph transformer decoder layer based on the graphs. TransMOT is not only more computationally efficient than the traditional Transformer, but it also achieves better tracking accuracy. To further improve the tracking speed and accuracy, we propose a cascade association framework to handle low-score detections and long-term occlusions that require large computational resources to model in TransMOT. The proposed method is evaluated on multiple benchmark datasets including MOT15, MOT16, MOT17, and MOT20, and it achieves state-of-the-art performance on all the datasets.