 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Solve the Limited Receptive Field for Monocular Depth Prediction
Paper and Code


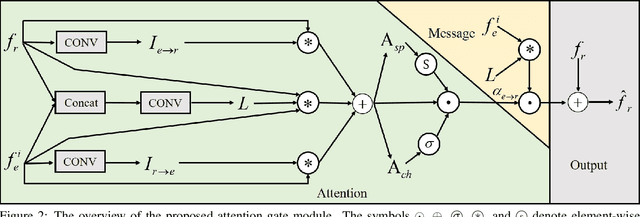

While convolutional neural networks have shown a tremendous impact on various computer vision tasks, they generally demonstrate limitations in explicitly modeling long-range dependencies due to the intrinsic locality of the convolution operation. Transformers, initially designed for natural language processing tasks, have emerged as alternative architectures with innate global self-attention mechanisms to capture long-range dependencies. In this paper, we propose TransDepth, an architecture which benefits from both convolutional neural networks and transformers. To avoid the network to loose its ability to capture local-level details due to the adoption of transformers, we propose a novel decoder which employs on attention mechanisms based on gates. Notably, this is the first paper which applies transformers into pixel-wise prediction problems involving continuous labels (i.e., monocular depth prediction and surface normal estimation). Extensive experiments demonstrate that the proposed TransDepth achieves state-of-the-art performance on three challenging datasets. The source code and trained models are available at https://github.com/ygjwd12345/TransDepth.