 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning suppresses simulation bias in predictive models built from sparse, multi-modal data
Paper and Code
Apr 19, 2021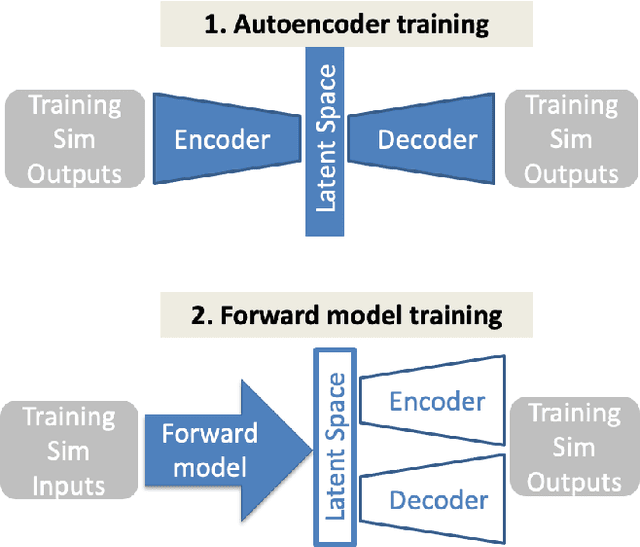
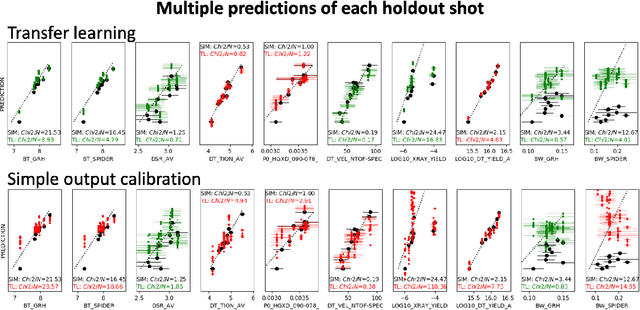
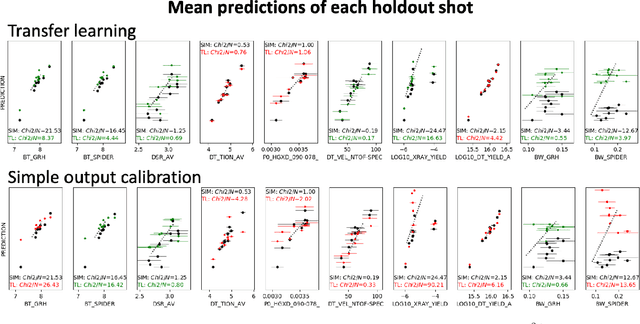
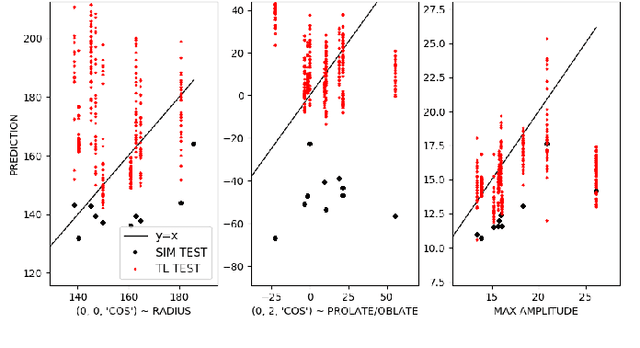
Many problems in science, engineering, and business require making predictions based on very few observations. To build a robust predictive model, these sparse data may need to be augmented with simulated data, especially when the design space is multidimensional. Simulations, however, often suffer from an inherent bias. Estimation of this bias may be poorly constrained not only because of data sparsity, but also because traditional predictive models fit only one type of observations, such as scalars or images, instead of all available data modalities, which might have been acquired and simulated at great cost. We combine recent developments in deep learning to build more robust predictive models from multimodal data with a recent, novel technique to suppress the bias, and extend it to take into account multiple data modalities. First, an initial, simulation-trained, neural network surrogate model learns important correlations between different data modalities and between simulation inputs and outputs. Then, the model is partially retrained, or transfer learned, to fit the observations. Using fewer than 10 inertial confinement fusion experiments for retraining, we demonstrate that this technique systematically improves simulation predictions while a simple output calibration makes predictions worse. We also offer extensive cross-validation with real and synthetic data to support our findings. The transfer learning method can be applied to other problems that require transferring knowledge from simulations to the domain of real observations. This paper opens up the path to model calibration using multiple data types, which have traditionally been ignored in predictive models.