 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Robust Deep Neural Networks via Adversarial Noise Propagation
Paper and Code

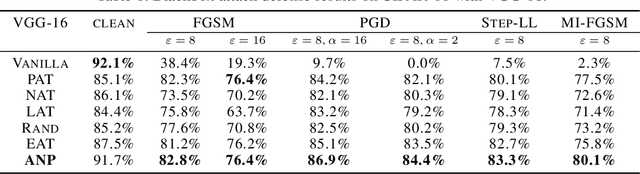
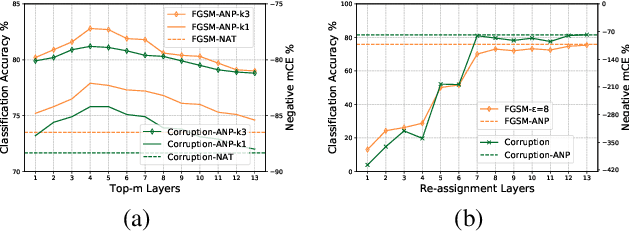
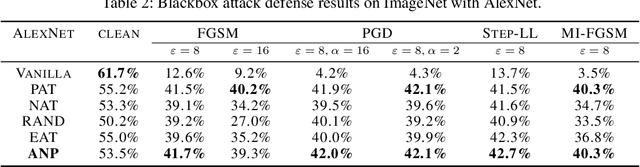
Deep neural networks have been found vulnerable to noises like adversarial examples and corruption in practice. A number of adversarial defense methods have been developed, which indeed improve the model robustness towards adversarial examples in practice. However, only relying on training with the data mixed with noises, most of them still fail to defend the generalized types of noises. Motivated by the fact that hidden layers play a very important role in maintaining a robust model, this paper comes up with a simple yet powerful training algorithm named Adversarial Noise Propagation (ANP) that injects diversified noises into the hidden layers in a layer-wise manner. We show that ANP can be efficiently implemented by exploiting the nature of the popular backward-forward training style for deep models. To comprehensively understand the behaviors and contributions of hidden layers, we further explore the insights from hidden representation insensitivity and human vision perception alignment. Extensive experiments on MNIST, CIFAR-10, CIFAR-10-C, CIFAR-10-P and ImageNet demonstrate that ANP enables the strong robustness for deep models against the generalized noises including both adversarial and corrupted ones, and significantly outperforms various adversarial defense methods.