 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Efficient Controllers via Analytic Policy Gradient
Paper and Code

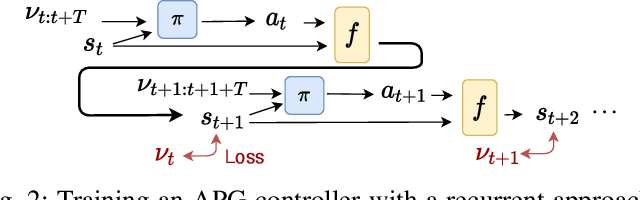
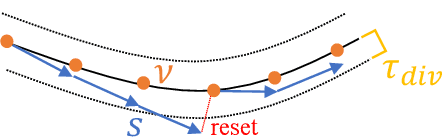
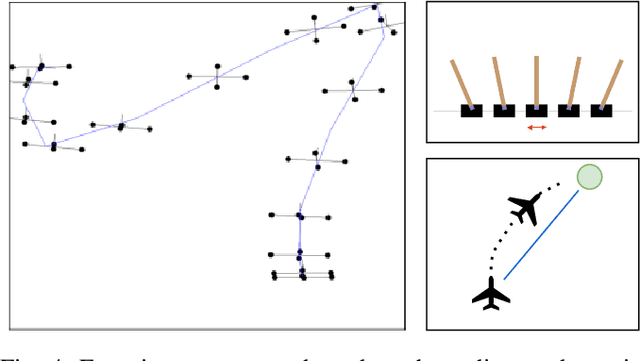
Control design for robotic systems is complex and often requires solving an optimization to follow a trajectory accurately. Online optimization approaches like Model Predictive Control (MPC) have been shown to achieve great tracking performance, but require high computing power. Conversely, learning-based offline optimization approaches, such as Reinforcement Learning (RL), allow fast and efficient execution on the robot but hardly match the accuracy of MPC in trajectory tracking tasks. In systems with limited compute, such as aerial vehicles, an accurate controller that is efficient at execution time is imperative. We propose an Analytic Policy Gradient (APG) method to tackle this problem. APG exploits the availability of differentiable simulators by training a controller offline with gradient descent on the tracking error. We address training instabilities that frequently occur with APG through curriculum learning and experiment on a widely used controls benchmark, the CartPole, and two common aerial robots, a quadrotor and a fixed-wing drone. Our proposed method outperforms both model-based and model-free RL methods in terms of tracking error. Concurrently, it achieves similar performance to MPC while requiring more than an order of magnitude less computation time. Our work provides insights into the potential of APG as a promising control method for robotics. To facilitate the exploration of APG, we open-source our code and make it available at https://github.com/lis-epfl/apg_trajectory_tracking.