 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scale-Aware Full Surround Monodepth with Transformers
Paper and Code
Jul 15, 2024

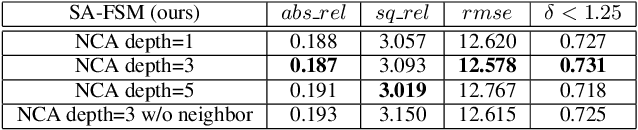
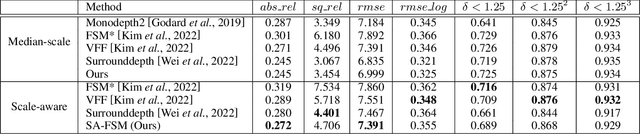
Full surround monodepth (FSM) methods can learn from multiple camera views simultaneously in a self-supervised manner to predict the scale-aware depth, which is more practical for real-world applications in contrast to scale-ambiguous depth from a standalone monocular camera. In this work, we focus on enhancing the scale-awareness of FSM methods for depth estimation. To this end, we propose to improve FSM from two perspectives: depth network structure optimization and training pipeline optimization. First, we construct a transformer-based depth network with neighbor-enhanced cross-view attention (NCA). The cross-attention modules can better aggregate the cross-view context in both global and neighboring views. Second, we formulate a transformer-based feature matching scheme with progressive training to improve the structure-from-motion (SfM) pipeline. That allows us to learn scale-awareness with sufficient matches and further facilitate network convergence by removing mismatches based on SfM loss. Experiments demonstrate that the resulting Scale-aware full surround monodepth (SA-FSM) method largely improves the scale-aware depth predictions without median-scaling at the test time, and performs favorably against the state-of-the-art FSM methods, e.g., surpassing SurroundDepth by 3.8% in terms of accuracy at delta<1.25 on the DDAD benchmark.