 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-Domain Named Entity Recognition via Neural Correction Models
Paper and Code
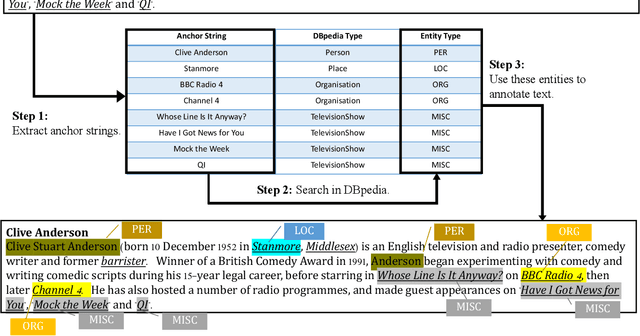
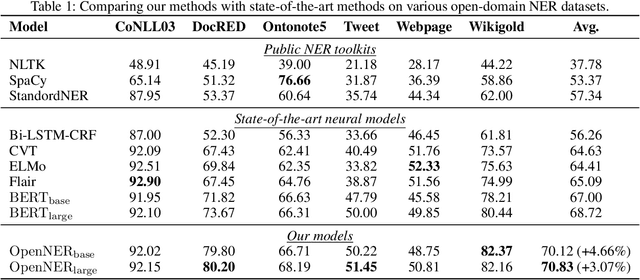
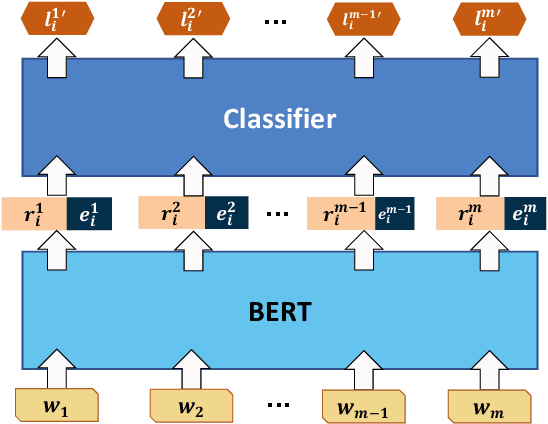
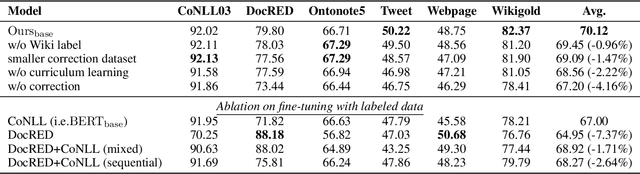
Named Entity Recognition (NER) plays an important role in a wide range of natural language processing tasks, such as relation extraction, question answering, etc. However, previous studies on NER are limited to a particular genre, using small manually-annotated or large but low-quality datasets. In this work, we propose a semi-supervised annotation framework to make full use of abstracts from Wikipedia and obtain a large and high-quality dataset called AnchorNER. We assume anchored strings in abstracts are named entities and annotate them with entity types mentioned in DBpedia. To improve the coverage, we design a neural correction model trained with a human-annotated NER dataset, DocRED, to correct the false-negative entity labels, and then train a BERT model with the corrected dataset. We evaluate our trained model on six NER datasets and our experimental results show that we have obtained state-of-the-art open-domain performances --- on top of the strong baselines BERT-base and BERT-large, we achieve relative improvements of 4.66% and 3.07% respectively.