 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Expressive Communication with Internet Memes: A New Multimodal Conversation Dataset and Benchmark
Paper and Code

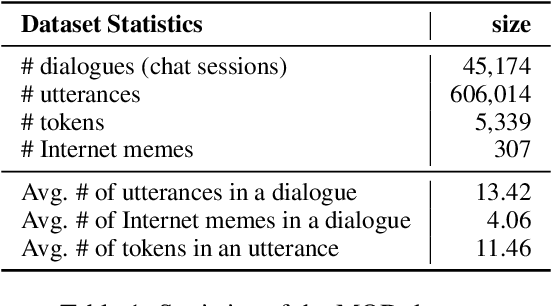

As a kind of new expression elements, Internet memes are popular and extensively used in online chatting scenarios since they manage to make dialogues vivid, moving, and interesting. However, most current dialogue researches focus on text-only dialogue tasks. In this paper, we propose a new task named as \textbf{M}eme incorporated \textbf{O}pen-domain \textbf{D}ialogue (MOD). Compared to previous dialogue tasks, MOD is much more challenging since it requires the model to understand the multimodal elements as well as the emotions behind them. To facilitate the MOD research, we construct a large-scale open-domain multimodal dialogue dataset incorporating abundant Internet memes into utterances. The dataset consists of $\sim$45K Chinese conversations with $\sim$606K utterances. Each conversation contains about $13$ utterances with about $4$ Internet memes on average and each utterance equipped with an Internet meme is annotated with the corresponding emotion. In addition, we present a simple and effective method, which utilizes a unified generation network to solve the MOD task. Experimental results demonstrate that our method trained on the proposed corpus is able to achieve expressive communication including texts and memes. The corpus and models have been publicly available at https://github.com/lizekang/DSTC10-MOD.