 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Multimodal Perception: Introducing the Touch-Language-Vision Dataset
Paper and Code

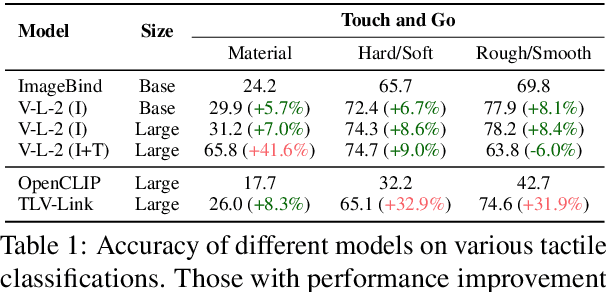
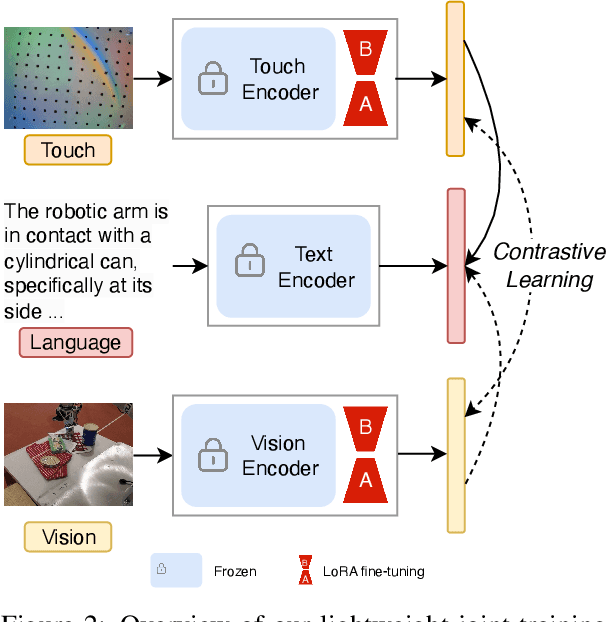
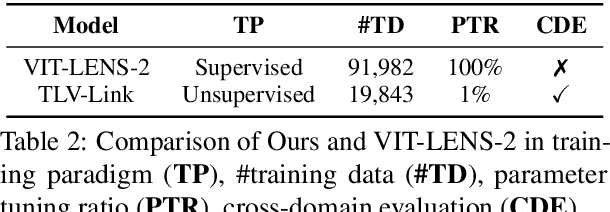
Tactility provides crucial support and enhancement for the perception and interaction capabilities of both humans and robots. Nevertheless, the multimodal research related to touch primarily focuses on visual and tactile modalities, with limited exploration in the domain of language. Beyond vocabulary, sentence-level descriptions contain richer semantics. Based on this, we construct a touch-language-vision dataset named TLV (Touch-Language-Vision) by human-machine cascade collaboration, featuring sentence-level descriptions for multimode alignment. The new dataset is used to fine-tune our proposed lightweight training framework, TLV-Link (Linking Touch, Language, and Vision through Alignment), achieving effective semantic alignment with minimal parameter adjustments (1%). Project Page: https://xiaoen0.github.io/touch.page/.