 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Construction of Diverse, High-quality Image Dataset
Paper and Code
Aug 22, 2017
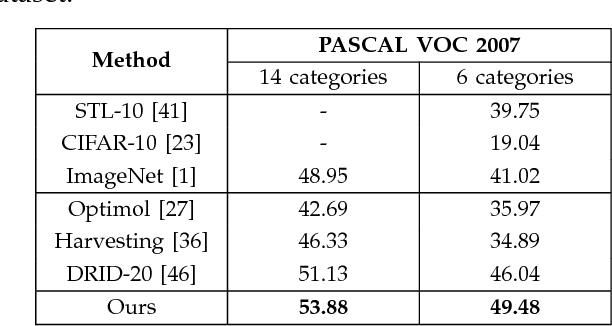


The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual metadata. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual metadata removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.