 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Imbalanced Learning with Deep Hierarchical Reinforcement Learning
Paper and Code
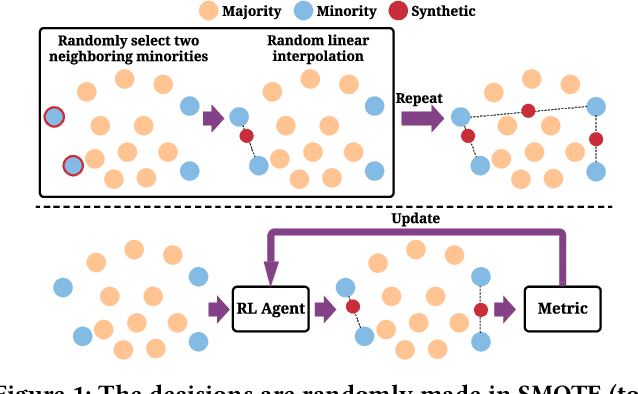

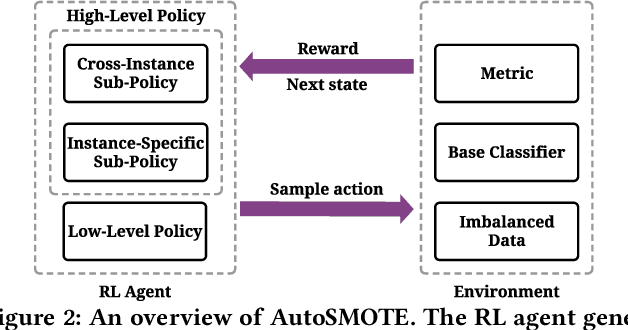

Imbalanced learning is a fundamental challenge in data mining, where there is a disproportionate ratio of training samples in each class. Over-sampling is an effective technique to tackle imbalanced learning through generating synthetic samples for the minority class. While numerous over-sampling algorithms have been proposed, they heavily rely on heuristics, which could be sub-optimal since we may need different sampling strategies for different datasets and base classifiers, and they cannot directly optimize the performance metric. Motivated by this, we investigate developing a learning-based over-sampling algorithm to optimize the classification performance, which is a challenging task because of the huge and hierarchical decision space. At the high level, we need to decide how many synthetic samples to generate. At the low level, we need to determine where the synthetic samples should be located, which depends on the high-level decision since the optimal locations of the samples may differ for different numbers of samples. To address the challenges, we propose AutoSMOTE, an automated over-sampling algorithm that can jointly optimize different levels of decisions. Motivated by the success of SMOTE~\cite{chawla2002smote} and its extensions, we formulate the generation process as a Markov decision process (MDP) consisting of three levels of policies to generate synthetic samples within the SMOTE search space. Then we leverage deep hierarchical reinforcement learning to optimize the performance metric on the validation data. Extensive experiments on six real-world datasets demonstrate that AutoSMOTE significantly outperforms the state-of-the-art resampling algorithms. The code is at https://github.com/daochenzha/autosmote