 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Theoretical Foundation of Policy Optimization for Learning Control Policies
Paper and Code
Oct 10, 2022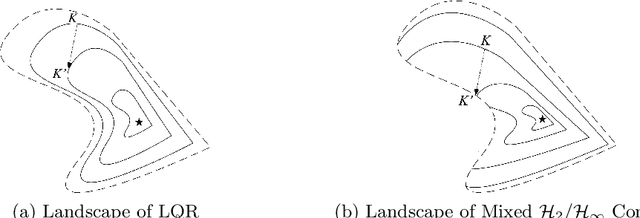
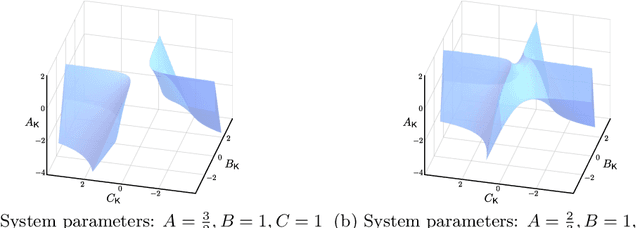
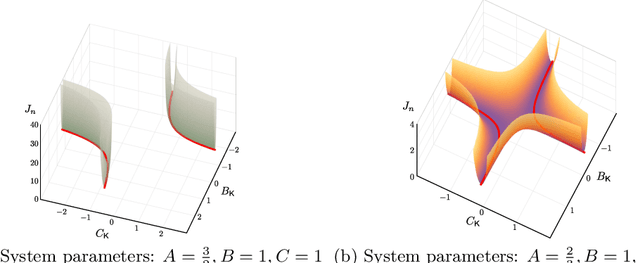
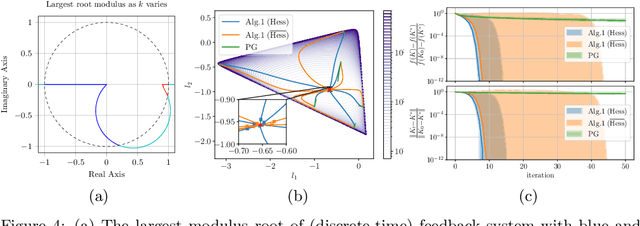
Gradient-based methods have been widely used for system design and optimization in diverse application domains. Recently, there has been a renewed interest in studying theoretical properties of these methods in the context of control and reinforcement learning. This article surveys some of the recent developments on policy optimization, a gradient-based iterative approach for feedback control synthesis, popularized by successes of reinforcement learning. We take an interdisciplinary perspective in our exposition that connects control theory, reinforcement learning, and large-scale optimization. We review a number of recently-developed theoretical results on the optimization landscape, global convergence, and sample complexity of gradient-based methods for various continuous control problems such as the linear quadratic regulator (LQR), $\mathcal{H}_\infty$ control, risk-sensitive control, linear quadratic Gaussian (LQG) control, and output feedback synthesis. In conjunction with these optimization results, we also discuss how direct policy optimization handles stability and robustness concerns in learning-based control, two main desiderata in control engineering. We conclude the survey by pointing out several challenges and opportunities at the intersection of learning and control.