 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Marker-free 3D Pose Estimation in Lifting: A Deep Multi-view Solution
Paper and Code
Feb 06, 2018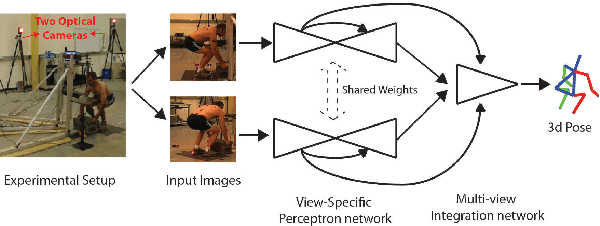
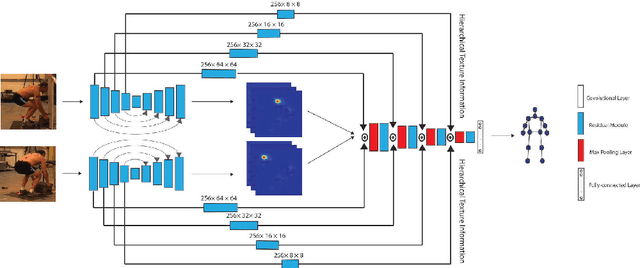
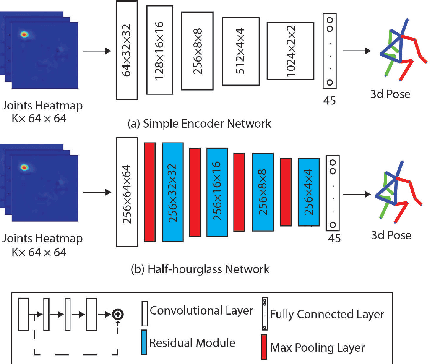
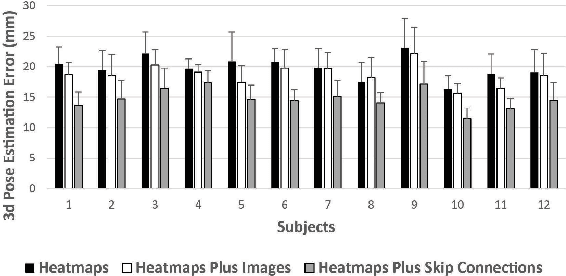
Lifting is a common manual material handling task performed in the workplaces. It is considered as one of the main risk factors for Work-related Musculoskeletal Disorders. To improve work place safety, it is necessary to assess musculoskeletal and biomechanical risk exposures associated with these tasks, which requires very accurate 3D pose. Existing approaches mainly utilize marker-based sensors to collect 3D information. However, these methods are usually expensive to setup, time-consuming in process, and sensitive to the surrounding environment. In this study, we propose a multi-view based deep perceptron approach to address aforementioned limitations. Our approach consists of two modules: a "view-specific perceptron" network extracts rich information independently from the image of view, which includes both 2D shape and hierarchical texture information; while a "multi-view integration" network synthesizes information from all available views to predict accurate 3D pose. To fully evaluate our approach, we carried out comprehensive experiments to compare different variants of our design. The results prove that our approach achieves comparable performance with former marker-based methods, i.e. an average error of $14.72 \pm 2.96$ mm on the lifting dataset. The results are also compared with state-of-the-art methods on HumanEva-I dataset, which demonstrates the superior performance of our approach.