 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPRDC: Task-Independent Privacy-Respecting Data Crowdsourcing Framework with Anonymized Intermediate Representations
Paper and Code
Jun 12, 2020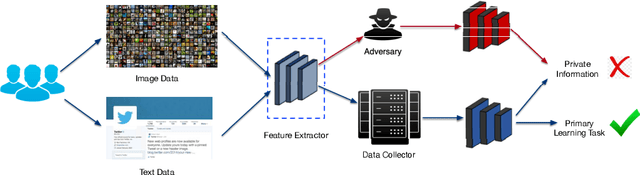
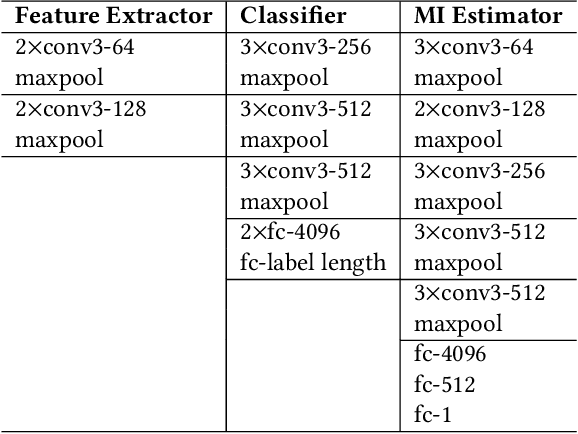
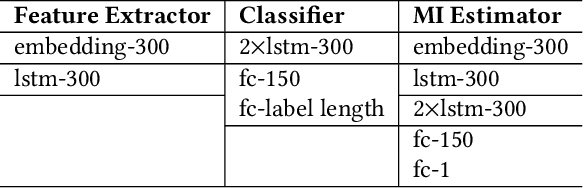
The success of deep learning partially benefits from the availability of various large-scale datasets. These datasets are often crowdsourced from individual users and contain private information like gender, age, etc. The emerging privacy concerns from users on data sharing hinder the generation or use of crowdsourcing datasets and lead to hunger of training data for new deep learning applications. One na\"{\i}ve solution is to pre-process the raw data to extract features at the user-side, and then only the extracted features will be sent to the data collector. Unfortunately, attackers can still exploit these extracted features to train an adversary classifier to infer private attributes. Some prior arts leveraged game theory to protect private attributes. However, these defenses are designed for known primary learning tasks, the extracted features work poorly for unknown learning tasks. To tackle the case where the learning task may be unknown or changing, we present TIPRDC, a task-independent privacy-respecting data crowdsourcing framework with anonymized intermediate representation. The goal of this framework is to learn a feature extractor that can hide the privacy information from the intermediate representations; while maximally retaining the original information embedded in the raw data for the data collector to accomplish unknown learning tasks. We design a hybrid training method to learn the anonymized intermediate representation: (1) an adversarial training process for hiding private information from features; (2) maximally retain original information using a neural-network-based mutual information estimator.