 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling Achieves $\tilde O$ Regret in Linear Quadratic Control
Paper and Code
Jun 17, 2022
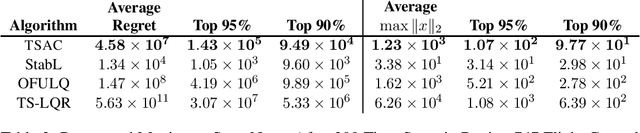

Thompson Sampling (TS) is an efficient method for decision-making under uncertainty, where an action is sampled from a carefully prescribed distribution which is updated based on the observed data. In this work, we study the problem of adaptive control of stabilizable linear-quadratic regulators (LQRs) using TS, where the system dynamics are unknown. Previous works have established that $\tilde O(\sqrt{T})$ frequentist regret is optimal for the adaptive control of LQRs. However, the existing methods either work only in restrictive settings, require a priori known stabilizing controllers, or utilize computationally intractable approaches. We propose an efficient TS algorithm for the adaptive control of LQRs, TS-based Adaptive Control, TSAC, that attains $\tilde O(\sqrt{T})$ regret, even for multidimensional systems, thereby solving the open problem posed in Abeille and Lazaric (2018). TSAC does not require a priori known stabilizing controller and achieves fast stabilization of the underlying system by effectively exploring the environment in the early stages. Our result hinges on developing a novel lower bound on the probability that the TS provides an optimistic sample. By carefully prescribing an early exploration strategy and a policy update rule, we show that TS achieves order-optimal regret in adaptive control of multidimensional stabilizable LQRs. We empirically demonstrate the performance and the efficiency of TSAC in several adaptive control tasks.