Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Deep Learning IIb: Optimization Properties of SGD
Paper and Code
Jan 07, 2018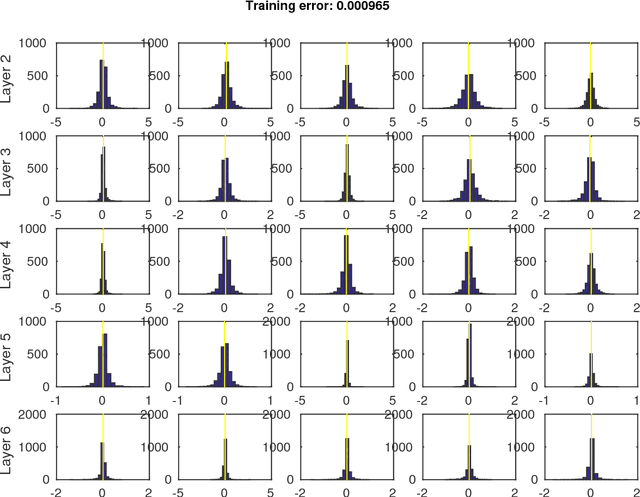

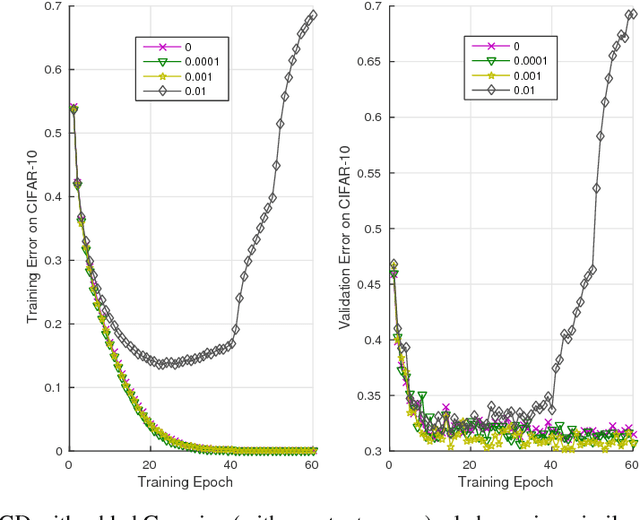

In Theory IIb we characterize with a mix of theory and experiments the optimization of deep convolutional networks by Stochastic Gradient Descent. The main new result in this paper is theoretical and experimental evidence for the following conjecture about SGD: SGD concentrates in probability -- like the classical Langevin equation -- on large volume, "flat" minima, selecting flat minimizers which are with very high probability also global minimizers
View paper on