 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Adaptivity in SGD: Self-Tuning Step Sizes with Unbounded Gradients and Affine Variance
Paper and Code
Feb 11, 2022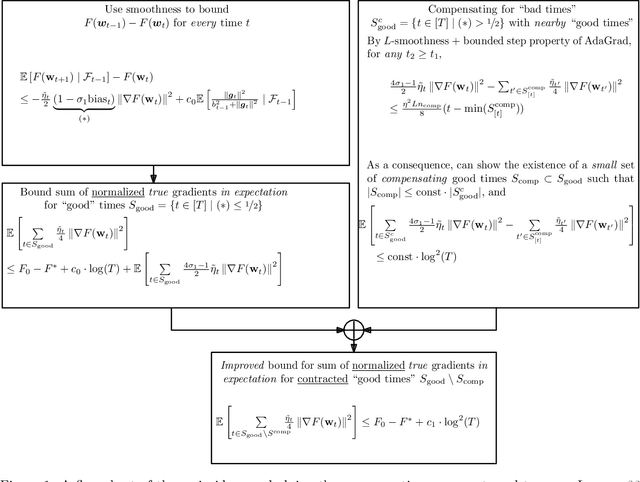

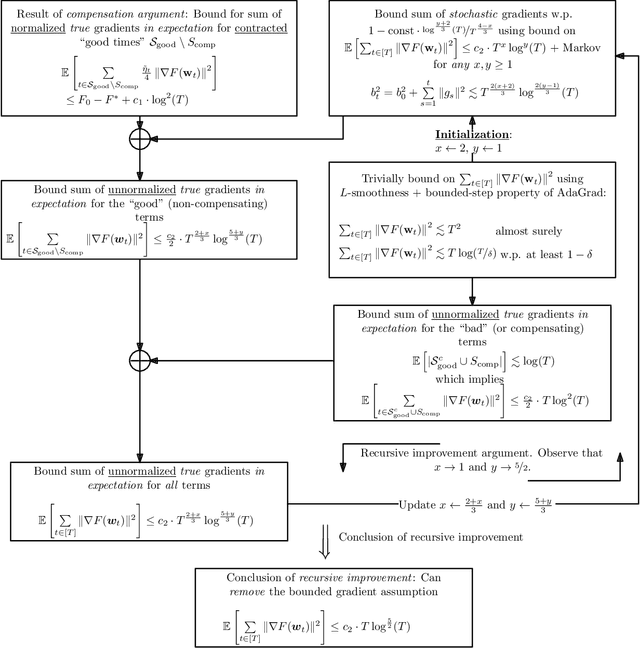
We study convergence rates of AdaGrad-Norm as an exemplar of adaptive stochastic gradient methods (SGD), where the step sizes change based on observed stochastic gradients, for minimizing non-convex, smooth objectives. Despite their popularity, the analysis of adaptive SGD lags behind that of non adaptive methods in this setting. Specifically, all prior works rely on some subset of the following assumptions: (i) uniformly-bounded gradient norms, (ii) uniformly-bounded stochastic gradient variance (or even noise support), (iii) conditional independence between the step size and stochastic gradient. In this work, we show that AdaGrad-Norm exhibits an order optimal convergence rate of $\mathcal{O}\left(\frac{\mathrm{poly}\log(T)}{\sqrt{T}}\right)$ after $T$ iterations under the same assumptions as optimally-tuned non adaptive SGD (unbounded gradient norms and affine noise variance scaling), and crucially, without needing any tuning parameters. We thus establish that adaptive gradient methods exhibit order-optimal convergence in much broader regimes than previously understood.