 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inductive Bias of Flatness Regularization for Deep Matrix Factorization
Paper and Code
Jun 22, 2023
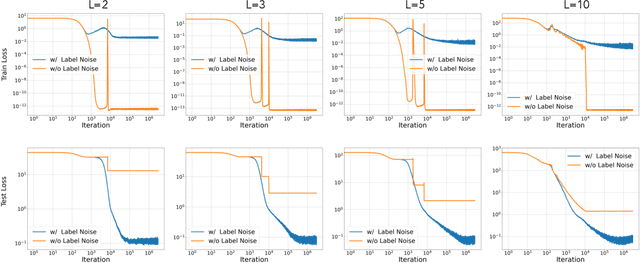
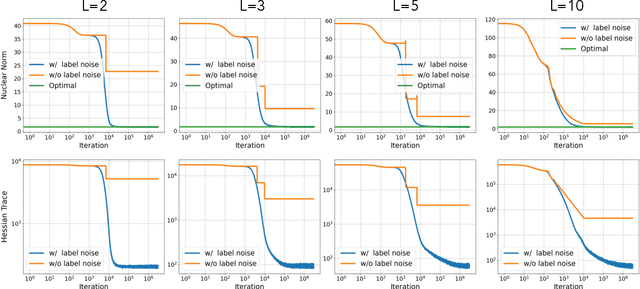
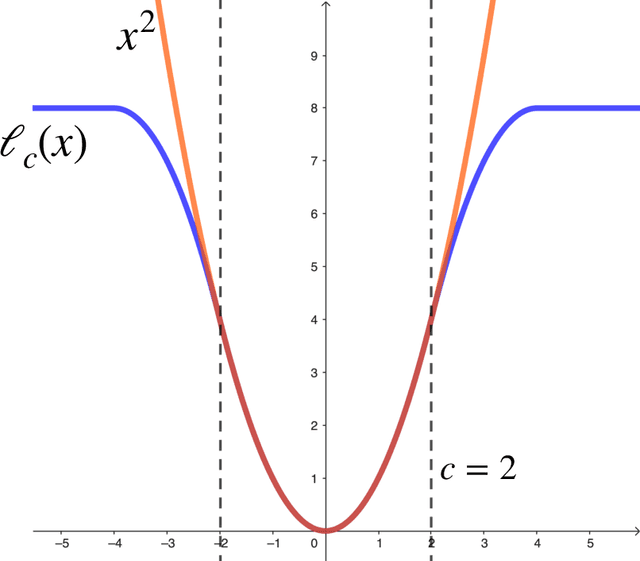
Recent works on over-parameterized neural networks have shown that the stochasticity in optimizers has the implicit regularization effect of minimizing the sharpness of the loss function (in particular, the trace of its Hessian) over the family zero-loss solutions. More explicit forms of flatness regularization also empirically improve the generalization performance. However, it remains unclear why and when flatness regularization leads to better generalization. This work takes the first step toward understanding the inductive bias of the minimum trace of the Hessian solutions in an important setting: learning deep linear networks from linear measurements, also known as \emph{deep matrix factorization}. We show that for all depth greater than one, with the standard Restricted Isometry Property (RIP) on the measurements, minimizing the trace of Hessian is approximately equivalent to minimizing the Schatten 1-norm of the corresponding end-to-end matrix parameters (i.e., the product of all layer matrices), which in turn leads to better generalization. We empirically verify our theoretical findings on synthetic datasets.