 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Socio-Cultural Differences for Annotating and Detecting the Affective States of Students
Paper and Code
Jan 12, 2019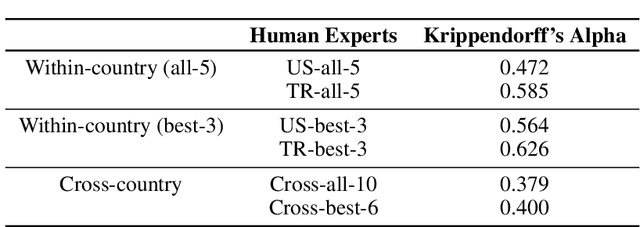
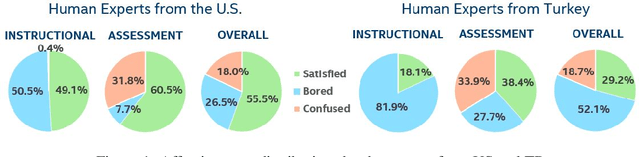
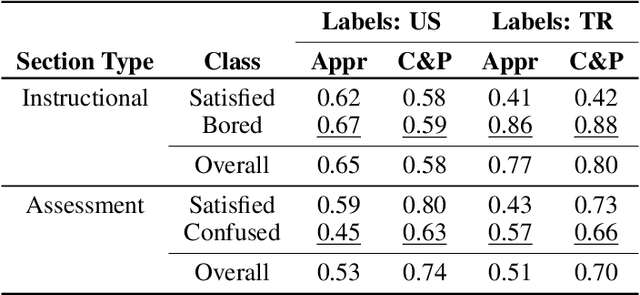
The development of real-time affect detection models often depends upon obtaining annotated data for supervised learning by employing human experts to label the student data. One open question in annotating affective data for affect detection is whether the labelers (i.e., human experts) need to be socio-culturally similar to the students being labeled, as this impacts the cost feasibility of obtaining the labels. In this study, we investigate the following research questions: For affective state annotation, how does the socio-cultural background of human expert labelers, compared to the subjects, impact the degree of consensus and distribution of affective states obtained? Secondly, how do differences in labeler background impact the performance of affect detection models that are trained using these labels?