 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cramer Distance as a Solution to Biased Wasserstein Gradients
Paper and Code

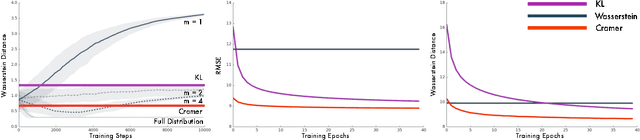


The Wasserstein probability metric has received much attention from the machine learning community. Unlike the Kullback-Leibler divergence, which strictly measures change in probability, the Wasserstein metric reflects the underlying geometry between outcomes. The value of being sensitive to this geometry has been demonstrated, among others, in ordinal regression and generative modelling. In this paper we describe three natural properties of probability divergences that reflect requirements from machine learning: sum invariance, scale sensitivity, and unbiased sample gradients. The Wasserstein metric possesses the first two properties but, unlike the Kullback-Leibler divergence, does not possess the third. We provide empirical evidence suggesting that this is a serious issue in practice. Leveraging insights from probabilistic forecasting we propose an alternative to the Wasserstein metric, the Cram\'er distance. We show that the Cram\'er distance possesses all three desired properties, combining the best of the Wasserstein and Kullback-Leibler divergences. To illustrate the relevance of the Cram\'er distance in practice we design a new algorithm, the Cram\'er Generative Adversarial Network (GAN), and show that it performs significantly better than the related Wasserstein GAN.