 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Loc: 3D Point Cloud Localization from Natural Language
Paper and Code
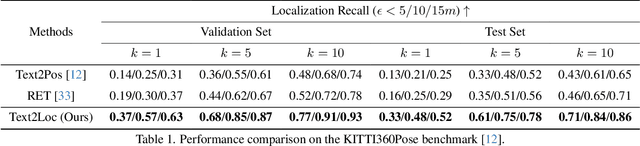

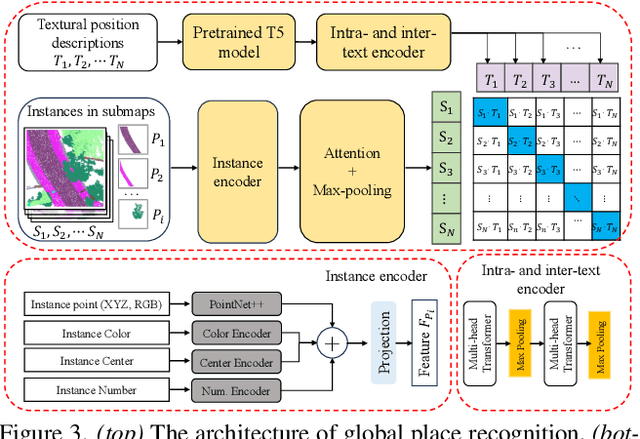
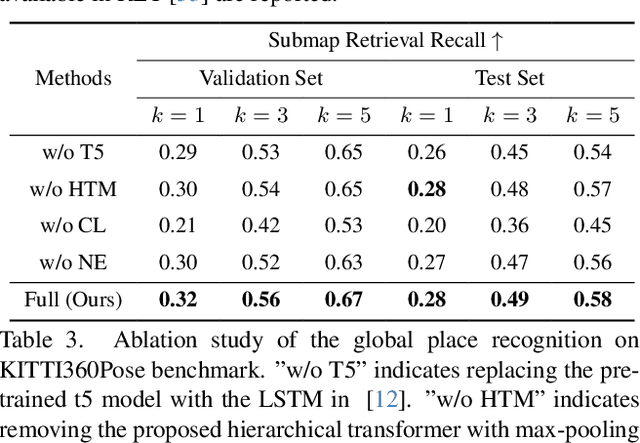
We tackle the problem of 3D point cloud localization based on a few natural linguistic descriptions and introduce a novel neural network, Text2Loc, that fully interprets the semantic relationship between points and text. Text2Loc follows a coarse-to-fine localization pipeline: text-submap global place recognition, followed by fine localization. In global place recognition, relational dynamics among each textual hint are captured in a hierarchical transformer with max-pooling (HTM), whereas a balance between positive and negative pairs is maintained using text-submap contrastive learning. Moreover, we propose a novel matching-free fine localization method to further refine the location predictions, which completely removes the need for complicated text-instance matching and is lighter, faster, and more accurate than previous methods. Extensive experiments show that Text2Loc improves the localization accuracy by up to $2\times$ over the state-of-the-art on the KITTI360Pose dataset. We will make the code publicly available.