 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTernary Neural Networks with Fine-Grained Quantization
Paper and Code
May 30, 2017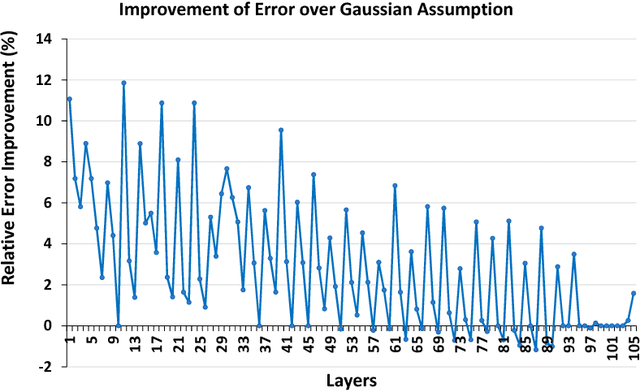
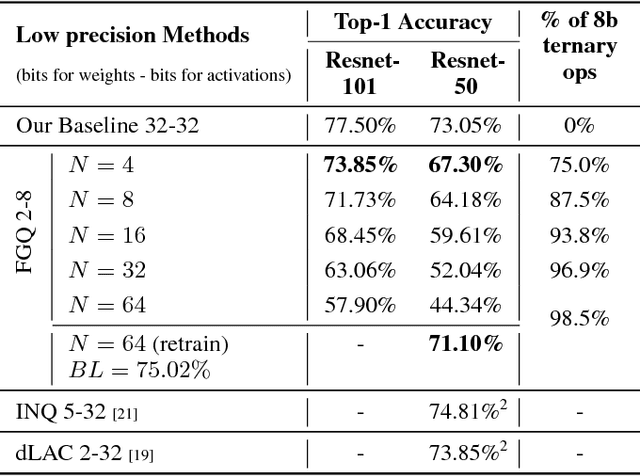
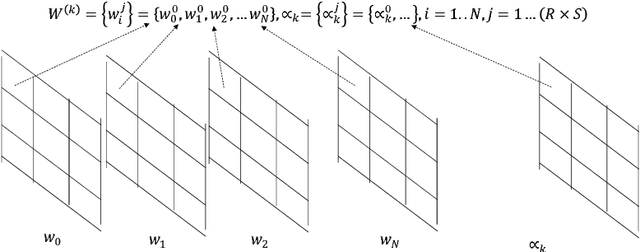
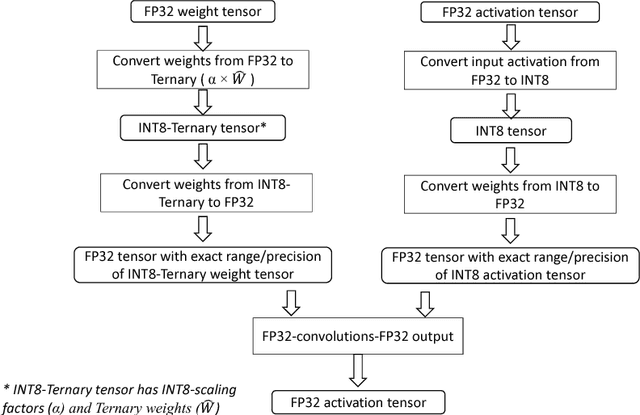
We propose a novel fine-grained quantization (FGQ) method to ternarize pre-trained full precision models, while also constraining activations to 8 and 4-bits. Using this method, we demonstrate a minimal loss in classification accuracy on state-of-the-art topologies without additional training. We provide an improved theoretical formulation that forms the basis for a higher quality solution using FGQ. Our method involves ternarizing the original weight tensor in groups of $N$ weights. Using $N=4$, we achieve Top-1 accuracy within $3.7\%$ and $4.2\%$ of the baseline full precision result for Resnet-101 and Resnet-50 respectively, while eliminating $75\%$ of all multiplications. These results enable a full 8/4-bit inference pipeline, with best-reported accuracy using ternary weights on ImageNet dataset, with a potential of $9\times$ improvement in performance. Also, for smaller networks like AlexNet, FGQ achieves state-of-the-art results. We further study the impact of group size on both performance and accuracy. With a group size of $N=64$, we eliminate $\approx99\%$ of the multiplications; however, this introduces a noticeable drop in accuracy, which necessitates fine tuning the parameters at lower precision. We address this by fine-tuning Resnet-50 with 8-bit activations and ternary weights at $N=64$, improving the Top-1 accuracy to within $4\%$ of the full precision result with $<30\%$ additional training overhead. Our final quantized model can run on a full 8-bit compute pipeline using 2-bit weights and has the potential of up to $15\times$ improvement in performance compared to baseline full-precision models.